 Jan Giacomelli
Jan Giacomelli
What is type checking? Why do we need it? What's the difference between static and runtime type checking?
Python is a strongly typed, dynamic programming language. With it being dynamically typed, types are dynamically inferred, so you can set variable values directly without defining the variable type like in statically typed programming languages such as Java.
name = "Michael"
String name = "Michael";
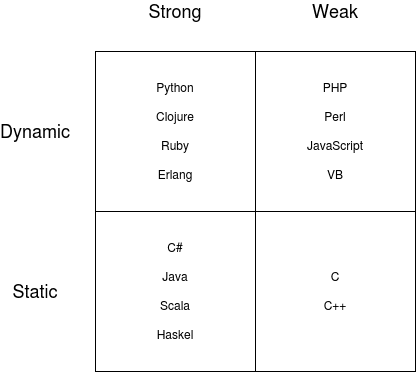
Strong and dynamic means that types are inferred at runtime, but you can't mix types. For example,
a = 1 + '0'will raise an error in Python. On the other hand, JavaScript is weak and dynamic, so types are inferred at runtime, and you can mix types. For example,a = 1 + '0'will setato10.
While dynamic typing brings flexibility, it isn't always desirable so, there have been a number of efforts as of late to bring static type inference to dynamic languages.
In this article, we'll look at what type hints are and how they can benefit you. We'll also dive into how you can use Python's type system for static type checking with mypy and runtime type checking with pydantic, marshmallow, and typeguard.
The Complete Python Guide:
Contents
Tools
There are a number of tools out there that use type hints for static and runtime type checking.
Static typing
Runtime type checking / data validation
Project specific
- Djantic
- django-stubs
- typeddjango
- flask-pydantic
- flask-marshmallow
- fastapi (pydantic is built in -- yay!)
Check out Awesome Python Typing for a full list of tools.
Type Hints
Type hints were added to Python in version 3.5.
They allow developers to annotate expected types for variables, function parameters, and function returns inside Python code. While such types are not enforced by the Python interpreter -- again, Python is a dynamically typed language -- they do offer a number of benefits. First and foremost, with type hints, you can better express the intent of what it is that your code is doing and how to use it. Better understanding results in fewer bugs.
For example, say you have the following function to calculate the average daily temperature:
def daily_average(temperatures):
return sum(temperatures) / len(temperatures)
As long as you provide a list of temperatures like so, the function works as intended, and it will return the expected result:
average_temperature = daily_average([22.8, 19.6, 25.9])
print(average_temperature) # => 22.76666666666667
What happens if you call the function with a dictionary where keys are timestamps of the measurements and values are temperatures?
average_temperature = daily_average({1599125906: 22.8, 1599125706: 19.6, 1599126006: 25.9})
print(average_temperature) # => 1599125872.6666667
Essentially, this function now returns the sum of keys / number of keys, which is clearly wrong. Since the function call didn't raise an error, this can go undetected especially if the end user provides the temperatures.
To avoid such confusion, you can add type hints by annotating the argument and return value:
def daily_average(temperatures: list[float]) -> float:
return sum(temperatures) / len(temperatures)
Now the function definition tells us:
temperaturesshould be a list of floats:temperatures: list[float]- the function should return a float:
-> float
print(daily_average.__annotations__)
# {'temperatures': list[float], 'return': <class 'float'>}
Type hints enable static type checking tools. Code editors and IDEs use them as well, warning you when usage of a particular function or method is not as expected according to the type hints and providing powerful autocompletion.
So, type hints are really just "hints". They are not as strict as type definitions in statically typed languages, in other words. That said, even though they are quite flexible, they still help to improve code quality by expressing intentions more clearly. Besides that you can use a lot of tools to benefit from them even more.
Type Annotations vs Type Hints
Type annotations are just syntax to annotate function inputs, function outputs, and variables:
def sum_xy(x: 'an integer', y: 'another integer') -> int:
return x + y
print(sum_xy.__annotations__)
# {'x': 'an integer', 'y': 'another integer', 'return': <class 'int'}
Type hints are built on top of annotations to make them more useful. Hints and annotations are often used interchangeably, but they are different.
Python's typing Module
You may be wondering why sometimes you see code like this:
from typing import List
def daily_average(temperatures: List[float]) -> float:
return sum(temperatures) / len(temperatures)
It's using the built-in float to define the function return type, but the List is imported from the typing module.
Before Python 3.9, the Python interpreter didn't support the use of built-ins with arguments for type hinting.
For example, it was possible to use list as a type hint like so:
def daily_average(temperatures: list) -> float:
return sum(temperatures) / len(temperatures)
But it wasn't possible to define the expected type of list elements (list[float]) without the typing module. The same can be said for dictionaries and other sequences and complex types:
from typing import Tuple, Dict
def generate_map(points: Tuple[float, float]) -> Dict[str, int]:
return map(points)
Besides that, the typing module allows you to define new types, type aliases, type Any and many other things.
For example, you may want to allow multiple types. For that you can use Union:
from typing import Union
def sum_ab(a: Union[int, float], b: Union[int, float]) -> Union[int, float]:
return a + b
Since Python 3.9 you can use built-ins like so:
def sort_names(names: list[str]) -> list[str]:
return sorted(names)
Since Python 3.10, you can use | to define union types:
def sum_ab(a: int | float, b: int | float) -> int | float:
return a + b
Static Type Checking with mypy
mypy is a tool for type checking at compile-time.
You can install it like any other Python package:
$ pip install mypy
To check your Python module you can run it like so:
$ python -m mypy my_module.py
So, let's look at the daily_average example again:
def daily_average(temperatures):
return sum(temperatures) / len(temperatures)
average_temperature = daily_average(
{1599125906: 22.8, 1599125706: 19.6, 1599126006: 25.9}
)
When type checking with mypy on such code, no errors will be reported since the function doesn't use type hints:
Success: no issues found in 1 source file
Add the type hints in:
def daily_average(temperatures: list[float]) -> float:
return sum(temperatures) / len(temperatures)
average_temperature = daily_average(
{1599125906: 22.8, 1599125706: 19.6, 1599126006: 25.9}
)
Run mypy again:
$ python -m mypy my_module.py
You should see:
my_module.py:6: error: Argument 1 to "daily_average" has incompatible
type "Dict[int, float]"; expected "List[float]" [arg-type]
Found 1 error in 1 file (checked 1 source file)
mypy recognized that the function was being called incorrectly. It reported the file name, line number, and description of the error. Using type hints in conjunction with mypy can help reduce the number of errors resulting from the misuse of functions, methods, and classes. This results in quicker feedback loops. You don't need to run all of your tests or even deploy the whole application. You're notified about such errors immediately.
It's also a good idea to add mypy to your CI pipeline as well to check typing before your code is merged or deployed. For more on this, review the Python Code Quality article.
Although it's a big improvement in terms of code quality, static type checking doesn't enforce types at runtime, as your program is running. That's why we also have runtime type checkers, which we'll look at next.
mypy comes with typeshed which contains external type annotations for the Python standard library and Python built-ins as well as third-party packages.
mypy checks Python programs with basically no runtime overhead. Although it checks types, duck typing still happens. Therefore, it cannot be used to compile CPython extensions.
Runtime Type Checking
pydantic
Static type checkers don't help when dealing with data from external sources like the users of your application. That's where runtime type checkers come into play. One such tool is pydantic, which is used to validate data. It raises validation errors when the provided data does not match a type defined with a type hint.
pydantic uses type casting to convert input data to force it to conform to the expected type.
$ pip install pydantic
It's actually quite simple to use. For example, let's define a Song class with a few attributes:
from datetime import date
from pydantic import BaseModel
class Song(BaseModel):
id: int
name: str
release: date
genres: list[str]
Now, when we initialize a new Song with valid data, everything works as expected:
song = Song(
id=101,
name='Bohemian Rhapsody',
release='1975-10-31',
genres=[
'Hard Rock',
'Progressive Rock'
]
)
print(song)
# id=101 name='Bohemian Rhapsody' release=datetime.date(1975, 10, 31)
# genres=['Hard Rock', 'Progressive Rock']
However, when we try to initialize a new Song with invalid data ('1975-31-31'), a ValidationError is raised:
song = Song(
id=101,
name='Bohemian Rhapsody',
release='1975-31-31',
genres=[
'Hard Rock',
'Progressive Rock'
]
)
print(song)
# pydantic_core._pydantic_core.ValidationError: 1 validation error for Song
# release
# Input should be a valid date or datetime, month value is outside expected range
# of 1-12 [type=date_from_datetime_parsing, input_value='1975-31-31', input_type=str]
# For further information visit
# https://errors.pydantic.dev/2.5/v/date_from_datetime_parsing
With pydantic, we can ensure that only data that matches the defined types are used in our application. This results not only in fewer bugs, but you'll need to write fewer tests as well. By using tools such as pydantic we don't need to write tests for cases where the user sends completely wrong data. It's handled by pydantic -- a ValidationError is raised. For example, FastAPI validates HTTP request and response bodies with pydantic:
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
price: float
@app.post('/items/', response_model=Item)
async def create_item(item: Item):
return item
The create_item handler expects a payload with a name (string) and price (float). The response object should look the same. Now, if there's an issue with the provided payload, an error is raised right away. Raising it late makes it harder to debug and to determine where the data of the wrong type came from. Plus, since it's handled by pydantic, you can keep your route handlers clean.
Along with leveraging type hints for data validation, you can also add custom validators to ensure correctness of data beyond its type. Adding custom validation for an attribute is fairly easy. For example, to prevent genre duplications in the Song class, you can add validation like so:
from datetime import date
from pydantic import BaseModel, field_validator
class Song(BaseModel):
id: int
name: str
release: date
genres: list[str]
@field_validator('genres')
def no_duplicates_in_genre(cls, v):
if len(set(v)) != len(v):
raise ValueError(
'No duplicates allowed in genre.'
)
return v
song = Song(
id=101,
name='Bohemian Rhapsody',
release='1975-10-31',
genres=[
'Hard Rock',
'Progressive Rock',
'Progressive Rock',
]
)
print(song)
# pydantic_core._pydantic_core.ValidationError: 1 validation error for Song
# genres
# Value error, No duplicates allowed in genre. [type=value_error,
# input_value=['Hard Rock', 'Progressiv...ck', 'Progressive Rock'], input_type=list]
# For further information visit https://errors.pydantic.dev/2.5/v/value_error
So, the validation method, no_duplicates_in_genre, must be decorated with field_validator, which takes the attribute name as an argument. The validation method must be a class method since validation happens before the instance is created. For data that fails validation, it should raise a standard Python ValueError.
You can also use validator methods to alter the value before validation occurs. To do so, use mode='before':
@field_validator('genres', mode='before')
For example, you can convert genres to lower case like so:
from datetime import date
from pydantic import BaseModel, field_validator
class Song(BaseModel):
id: int
name: str
release: date
genres: list[str]
@field_validator('genres', mode='before')
def to_lower_case(cls, v):
return [genre.lower() for genre in v]
@field_validator('genres')
def no_duplicates_in_genre(cls, v):
if len(set(v)) != len(v):
raise ValueError(
'No duplicates allowed in genre.'
)
return v
song = Song(
id=101,
name='Bohemian Rhapsody',
release='1975-10-31',
genres=[
'Hard Rock',
'PrOgReSsIvE ROCK',
'Progressive Rock',
]
)
print(song)
# pydantic_core._pydantic_core.ValidationError: 1 validation error for Song
# genres
# Value error, No duplicates allowed in genre.
# [type=value_error, input_value=['Hard Rock', 'PrOgReSsIv...CK', 'Progressive Rock'], input_type=list]
# For further information visit https://errors.pydantic.dev/2.5/v/value_error
to_lower_case converts every element in the genres list to lowercase. Because of mode='before', this method is called before pydantic validates the types. All genres are converted to lowercase and then validated with no_duplicates_in_genre.
pydantic also offers more strict types like StrictStr and EmailStr to make your validations even better. Review Field Types from the docs for more on this.
Marshmallow
Another tool worth mentioning is marshmallow, which helps to validate complex data and load/dump data from/to native Python types. Installation is the same as for any other Python package:
$ pip install marshmallow
Like pydantic, you can add type validation to a class:
from marshmallow import Schema, fields, post_load
class Song:
def __init__(
self,
id,
name,
release,
genres
):
self.id = id
self.name = name
self.release = release
self.genres = genres
def __repr__(self):
return (
f'<Song(id={self.id}, name={self.name}), '
f'release={self.release.isoformat()}, genres={self.genres}>'
)
class SongSchema(Schema):
id = fields.Int()
name = fields.Str()
release = fields.Date()
genres = fields.List(fields.String())
@post_load
def make_song(self, data, **kwargs):
return Song(**data)
external_data = {
'id': 101,
'name': 'Bohemian Rhapsody',
'release': '1975-10-31',
'genres': ['Hard Rock', 'Progressive Rock']
}
song = SongSchema().load(external_data)
print(song)
# <Song(id=101, name=Bohemian Rhapsody), release=1975-10-31, genres=['Hard Rock', 'Progressive Rock']>
Unlike pydantic, marshmallow doesn't use type casting, so you need to define the schema and class separately. For example, release date in external_data must be an ISO string. It doesn't work with a datetime object.
To enable deserializing data into a Song object, you need to add a method decorated with @post_load decorator to the schema:
class SongSchema(Schema):
id = fields.Int()
name = fields.Str()
release = fields.Date()
genres = fields.List(fields.String(), validate=no_duplicates)
@post_load
def make_song(self, data, **kwargs):
return Song(**data)
The schema validates the data and if all fields are valid, it creates an instance of the class by calling make_song with the validated data.
Like pydantic, you can add custom validations for each attribute from the schema. For example, you can prevent duplicates like so:
import datetime
from marshmallow import Schema, fields, post_load, ValidationError
class Song:
def __init__(
self,
id,
name,
release,
genres
):
self.id = id
self.name = name
self.release = release
self.genres = genres
def __repr__(self):
return (
f'<Song(id={self.id}, name={self.name}), '
f'release={self.release.isoformat()}, genres={self.genres}>'
)
def no_duplicates(genres):
if isinstance(genres, list):
genres = [
genre.lower()
for genre in genres
if isinstance(genre, str)
]
if len(set(genres)) != len(genres):
raise ValidationError(
'No duplicates allowed in genres.'
)
class SongSchema(Schema):
id = fields.Int()
name = fields.Str()
release = fields.Date()
genres = fields.List(fields.String(), validate=no_duplicates)
@post_load
def make_song(self, data, **kwargs):
return Song(**data)
external_data = {
'id': 101,
'name': 'Bohemian Rhapsody',
'release': '1975-10-31',
'genres': ['Hard Rock', 'Progressive Rock', 'ProgressivE Rock']
}
song = SongSchema().load(external_data)
print(song)
# marshmallow.exceptions.ValidationError:
# {'genres': ['No duplicates allowed in genres.']}
As you can see, you can use either pydantic or marshmallow to ensure data has the correct type as your application runs. Pick the one that fits your style better.
Typeguard
While pydantic and marshmallow focus on data validation and serialization, typeguard focuses on checking types as functions are called. While mypy just does static type checking, typeguard enforces types while your program is running.
$ pip install typeguard
Let's take a look at the same example as before -- a Song class. This time we define it's __init__ method with type hinted arguments:
from datetime import date
from typeguard import typechecked
@typechecked
class Song:
def __init__(
self,
id: int,
name: str,
release: date,
genres: list[str]
) -> None:
self.id = id
self.name = name
self.release = release
self.genres = genres
song = Song(
id=101,
name='Bohemian Rhapsody',
release=date(1975, 10, 31),
genres={
'Hard Rock',
'Progressive Rock',
}
)
print(song)
# typeguard.TypeCheckError: argument "genres" (set) is not a list
The typechecked decorator can be used for both classes and functions when you want to enforce type checking during runtime. Running this code will raise a TypeError since genres are a set instead of a list. You can similarly use a decorator for functions like so:
from typeguard import typechecked
@typechecked
def sum_ab(a: int, b: int) -> int:
return a + b
It also comes with a pytest plugin. To check types for package my_package while running tests you can run this command:
$ python -m pytest --typeguard-packages=my_package
When running with pytest you don't need to use the @typechecked decorator. So, you can either decorate your functions and classes to enforce types during runtime or just during test runs. Either way, typeguard can be a powerful safety net for your application to ensure it runs as expected.
Flask with pydantic
So let's put it all together into a web application. As mentioned above, FastAPI uses pydantic by default. Although Flask doesn't have built-in support for pydantic we can use bindings to also add it to our APIs. So let's create a new Flask project to see it in action.
First, create a new folder:
$ mkdir flask_example
$ cd flask_example
Next, initialize your project with Poetry:
$ poetry init
Package name [flask_example]:
Version [0.1.0]:
Description []:
Author [Your name <[email protected]>, n to skip]:
License []:
Compatible Python versions [^3.12]: >3.12
Would you like to define your main dependencies interactively? (yes/no) [yes] no
Would you like to define your development dependencies interactively? (yes/no) [yes] no
Do you confirm generation? (yes/no) [yes]
After that, add Flask, Flask-Pydantic, and pytest:
$ poetry add flask Flask-Pydantic
$ poetry add --dev pytest
Create a file to hold our tests called test_app.py:
import json
import pytest
from app import app
@pytest.fixture
def client():
app.config['TESTING'] = True
with app.test_client() as client:
yield client
def test_create_todo(client):
response = client.post(
'/todos/',
data=json.dumps(
{
'title': 'Wash the dishes',
'done': False,
'deadline': '2020-12-12'
}
),
content_type='application/json'
)
assert response.status_code == 201
def test_create_todo_bad_request(client):
response = client.post(
'/todos/',
data=json.dumps(
{
'title': 'Wash the dishes',
'done': False,
'deadline': 'WHENEVER'
}
),
content_type='application/json'
)
assert response.status_code == 400
Here, we have two tests for creating new todos. One checks that a status of 201 is returned when everything is fine. Another checks that a status of 400 is returned when the provided data is not as expected.
Next, add a file for the Flask app called app.py:
import datetime
from flask import Flask, request
from flask_pydantic import validate
from pydantic import BaseModel
app = Flask(__name__)
class CreateTodo(BaseModel):
title: str
done: bool
deadline: datetime.date
class Todo(BaseModel):
title: str
done: bool
deadline: datetime.date
created_at: datetime.datetime
@app.route('/todos/', methods=['POST'])
@validate(body=CreateTodo)
def todos():
todo = Todo(
title=request.body_params.title,
done=request.body_params.done,
deadline=request.body_params.deadline,
created_at=datetime.datetime.now()
)
return todo, 201
if __name__ == '__main__':
app.run()
We've defined an endpoint for creating todos along with a request schema called CreateTodo and a response schema called Todo. Now when data is sent to the API that does not match the request schema a status of 400 with validation errors in the body is returned. You can run tests now to check that your API is actually behaving as described:
$ poetry run pytest
Running Type Checkers
Now that you know the tools, the next question is: When should they be used?
Much like code quality tools, you typically run type checkers:
- While coding (inside your IDE or code editor)
- At commit time (with pre-commit hooks)
- When code is checked in to source control (via a CI pipeline)
- During program run (runtime checkers)
Inside Your IDE or Code Editor
It's best to check for issues that could have a negative impact on quality early and often. Therefore, it's recommended to statically check your code during development. Many of the popular IDEs have mypy or mypy-like static type checkers built in. For those that don't, there's likely a plugin available. Such plugins warn you in real-time about type violations and potential programming errors.
Resources:
Pre-commit Hooks
Since you'll inevitably miss a warning here and there as you're coding, it's a good practice to check for static type issues at commit time with pre-commit git hooks. This way you can avoid committing code that won't pass type checks inside your CI pipeline.
The pre-commit framework is recommended for managing git hooks.
$ pip install pre-commit
Once installed, add a pre-commit config file called .pre-commit-config.yaml to your project. To run mypy, add the following config:
repos:
- repo: https://github.com/pre-commit/mirrors-mypy
rev: 'v1.7.1'
hooks:
- id: mypy
Finally, to set up the git hook scripts:
(venv)$ pre-commit install
Now, every time you run git commit mypy will run before the actual commit is made. And if there are any issues, the commit will be aborted.
CI Pipeline
It makes sense to run static type checks inside your CI pipeline to prevent type issues from being merged into the code base. This is probably the most important time to run mypy or some other static type checker.
You may experience issues when running static type checks with mypy, especially when using third-party libraries without type hints. That's probably the major reason why many people avoid running mypy checks inside the CI pipeline.
During Program Run
All previous times to run are before your program is actually running. That's the job for static type checkers. For dynamic type checkers you need a running program. As mentioned before, using them will require fewer tests, produce less bugs, and help you detect bugs early. You can use them for data validations (with pydantic and marshmallow) and to enforce types during program run (with typeguard).
Conclusion
Type checking may seem unnecessary when a code base is small, but the larger it gets, the more important it is. It's one more layer that protects us against easily preventable bugs. Type hints, although they're not enforced by the interpreter, help to better express the intent of a variable, function, or class. Most modern IDEs and code editors provide plugins to notify developers about type mismatches based on type hints. To enforce them, we can include mypy into our workflow to statically check whether usage of methods match their type hints. Although static analysis can improve your code, you must take into account that our software is communicating with the external world. Because of that, it's encouraged to add runtime type checkers like pydantic or marshmallow. They help with validating user input and raise errors at the earliest possible stage. The faster you find an error, the easier it is to correct it and move on.
The Complete Python Guide: