 Jan Giacomelli
Jan Giacomelli
Testing production grade code is hard. Sometimes it can take nearly all of your time during feature development. What's more, even when you have 100% coverage and tests are green, you still may not feel confident that the new feature will work properly in production.
This guide will take you through the development of an application using Test-Driven Development (TDD). We'll look at how and what you should test. We'll use pytest for testing, pydantic to validate data and reduce the number of tests required, and Flask to provide an interface for our clients via a RESTful API. By the end, you'll have a solid pattern that you can use for any Python project so that you can have confidence that passing tests actually mean working software.
The Complete Python Guide:
Contents
Objectives
By the end of this article, you will be able to:
- Explain how you should test your software
- Configure pytest and set up a project structure for testing
- Define database models with pydantic
- Use pytest fixtures for managing test state and performing side effects
- Verify JSON responses against JSON Schema definitions
- Organize database operations with commands (modify state, has side effects) and queries (read-only, no side effects)
- Write unit, integration, and end-to-end tests with pytest
- Explain why it's important to focus your testing efforts on testing behavior rather than implementation details
How Should I Test My Software?
Software developers tend to be very opinionated about testing. Because of this, they have differing opinions about how important testing is and ideas on how to go about doing it. That said, let's look at three guidelines that (hopefully) most developers will agree with that will help you write valuable tests:
-
Tests should tell you the expected behavior of the unit under test. Therefore, it's advisable to keep them short and to the point. The GIVEN, WHEN, THEN structure can help with this:
- GIVEN - what are the initial conditions for the test?
- WHEN - what is occurring that needs to be tested?
- THEN - what is the expected response?
So you should prepare your environment for testing, execute the behavior, and, at the end, check that output meets expectations. -
Each piece of behavior should be tested once -- and only once. Testing the same behavior more than once does not mean that your software is more likely to work. Tests need to be maintained too. If you make a small change to your code base and then twenty tests break, how do you know which functionality is broken? When only a single test fails, it's much easier to find the bug.
-
Each test must be independent from other tests. Otherwise, you'll have hard time maintaining and running the test suite.
This guide is opinionated too. Don't take anything as a holy grail or silver bullet. Feel free to get in touch on Twitter (@jangiacomelli) to discuss anything related to this guide.
Basic Setup
With that, let's get our hands dirty. You're ready to see what all of this means in the real world. The most simple test with pytest looks like this:
def another_sum(a, b):
return a + b
def test_another_sum():
assert another_sum(3, 2) == 5
That's the example that you've probably already seen at least once. First of all, you'll never write tests inside your code base so let's split this into two files and packages.
Create a new directory for this project and move into it:
$ mkdir testing_project
$ cd testing_project
Next, create (and activate) a virtual environment.
For more on managing dependencies and virtual environments, check out Modern Python Environments.
Third, install pytest:
(venv)$ pip install pytest
After that, create a new folder called "sum". Add an __init__.py to the new folder, to turn it into a package, along with a another_sum.py file:
def another_sum(a, b):
return a + b
Add another folder named "tests" and add the following files and folders:
└── tests
├── __init__.py
└── test_sum
├── __init__.py
└── test_another_sum.py
You should now have:
├── sum
│ ├── __init__.py
│ └── another_sum.py
└── tests
├── __init__.py
└── test_sum
├── __init__.py
└── test_another_sum.py
In test_another_sum.py add:
from sum.another_sum import another_sum
def test_another_sum():
assert another_sum(3, 2) == 5
Next, add an empty conftest.py file, which is used for storing pytest fixtures, inside the "tests" folder.
Finally, add a pytest.ini -- a pytest configuration file -- to the "tests" folder, which can also be empty as this point.
The full project structure should now look like:
├── sum
│ ├── __init__.py
│ └── another_sum.py
└── tests
├── __init__.py
├── conftest.py
├── pytest.ini
└── test_sum
├── __init__.py
└── test_another_sum.py
Keeping your tests together in single package allows you to:
- Reuse pytest configuration across all tests
- Reuse fixtures across all tests
- Simplify the running of tests
You can run all the tests with this command:
(venv)$ python -m pytest tests
You should see results of the tests, which in this case is for test_another_sum:
============================== test session starts ==============================
platform darwin -- Python 3.10.1, pytest-7.0.1, pluggy-1.0.0
rootdir: /testing_project/tests, configfile: pytest.ini
collected 1 item
tests/test_sum.py/test_another_sum.py . [100%]
=============================== 1 passed in 0.01s ===============================
Real Application
Now that you have the basic idea behind how to set up and structure tests, let's build a simple blog application. We'll build it using TDD to see testing in action. We'll use Flask for our web framework and, to focus on testing, SQLite for our database.
Our app will have the following requirements:
- articles can be created
- articles can be fetched
- articles can be listed
First, let's create a new project:
$ mkdir blog_app
$ cd blog_app
Second, create (and activate) a virtual environment.
Third, install pytest and pydantic, a data parsing and validation library:
(venv)$ pip install pytest && pip install "pydantic[email]"
pip install "pydantic[email]"installs pydantic along with email-validator, which will be used for validating email addresses.
Next, create the following files and folders:
blog_app
├── blog
│ ├── __init__.py
│ ├── app.py
│ └── models.py
└── tests
├── __init__.py
├── conftest.py
└── pytest.ini
Add the following code to models.py to define a new Article model with pydantic:
import os
import sqlite3
import uuid
from typing import List
from pydantic import BaseModel, EmailStr, Field
class NotFound(Exception):
pass
class Article(BaseModel):
id: str = Field(default_factory=lambda: str(uuid.uuid4()))
author: EmailStr
title: str
content: str
@classmethod
def get_by_id(cls, article_id: str):
con = sqlite3.connect(os.getenv("DATABASE_NAME", "database.db"))
con.row_factory = sqlite3.Row
cur = con.cursor()
cur.execute("SELECT * FROM articles WHERE id=?", (article_id,))
record = cur.fetchone()
if record is None:
raise NotFound
article = cls(**record) # Row can be unpacked as dict
con.close()
return article
@classmethod
def get_by_title(cls, title: str):
con = sqlite3.connect(os.getenv("DATABASE_NAME", "database.db"))
con.row_factory = sqlite3.Row
cur = con.cursor()
cur.execute("SELECT * FROM articles WHERE title = ?", (title,))
record = cur.fetchone()
if record is None:
raise NotFound
article = cls(**record) # Row can be unpacked as dict
con.close()
return article
@classmethod
def list(cls) -> List["Article"]:
con = sqlite3.connect(os.getenv("DATABASE_NAME", "database.db"))
con.row_factory = sqlite3.Row
cur = con.cursor()
cur.execute("SELECT * FROM articles")
records = cur.fetchall()
articles = [cls(**record) for record in records]
con.close()
return articles
def save(self) -> "Article":
with sqlite3.connect(os.getenv("DATABASE_NAME", "database.db")) as con:
cur = con.cursor()
cur.execute(
"INSERT INTO articles (id,author,title,content) VALUES(?, ?, ?, ?)",
(self.id, self.author, self.title, self.content)
)
con.commit()
return self
@classmethod
def create_table(cls, database_name="database.db"):
conn = sqlite3.connect(database_name)
conn.execute(
"CREATE TABLE IF NOT EXISTS articles (id TEXT, author TEXT, title TEXT, content TEXT)"
)
conn.close()
This is an Active Record-style model, which provides methods for storing, fetching a single article, and listing all articles.
You may be wondering why we didn't write tests to cover the model. We'll get to the why shortly.
Create a New Article
Next, let's cover our business logic. We'll write some helper commands and queries to separate our logic from the model and API. Since we're using pydantic, we can easily validate data based on our model.
Create a "test_article" package in the "tests" folder. Then, add a file called test_commands.py to it.
blog_app
├── blog
│ ├── __init__.py
│ ├── app.py
│ └── models.py
└── tests
├── __init__.py
├── conftest.py
├── pytest.ini
└── test_article
├── __init__.py
└── test_commands.py
Add the following tests to test_commands.py:
import pytest
from blog.models import Article
from blog.commands import CreateArticleCommand, AlreadyExists
def test_create_article():
"""
GIVEN CreateArticleCommand with valid author, title, and content properties
WHEN the execute method is called
THEN a new Article must exist in the database with the same attributes
"""
cmd = CreateArticleCommand(
author="[email protected]",
title="New Article",
content="Super awesome article"
)
article = cmd.execute()
db_article = Article.get_by_id(article.id)
assert db_article.id == article.id
assert db_article.author == article.author
assert db_article.title == article.title
assert db_article.content == article.content
def test_create_article_already_exists():
"""
GIVEN CreateArticleCommand with a title of some article in database
WHEN the execute method is called
THEN the AlreadyExists exception must be raised
"""
Article(
author="[email protected]",
title="New Article",
content="Super extra awesome article"
).save()
cmd = CreateArticleCommand(
author="[email protected]",
title="New Article",
content="Super awesome article"
)
with pytest.raises(AlreadyExists):
cmd.execute()
These tests cover the following business use cases:
- articles should be created for valid data
- article title must be unique
Run the tests from your project directory to see that they fail:
(venv)$ python -m pytest tests
Now we can implement our command.
Add a commands.py file to the "blog" folder:
from pydantic import BaseModel, EmailStr
from blog.models import Article, NotFound
class AlreadyExists(Exception):
pass
class CreateArticleCommand(BaseModel):
author: EmailStr
title: str
content: str
def execute(self) -> Article:
try:
Article.get_by_title(self.title)
raise AlreadyExists
except NotFound:
pass
article = Article(
author=self.author,
title=self.title,
content=self.content
).save()
return article
Test Fixtures
We can use pytest fixtures to clear the database after each test and create a new one before each test. Fixtures are functions decorated with a @pytest.fixture decorator. They are usually located inside conftest.py but they can be added to the actual test files as well. These functions are executed by default before each test.
One option is to use their returned values inside your tests. For example:
import random
import pytest
@pytest.fixture
def random_name():
names = ["John", "Jane", "Marry"]
return random.choice(names)
def test_fixture_usage(random_name):
assert random_name
So, to use the value returned from the fixture inside the test you just need to add the name of the fixture function as a parameter to the test function.
Another option is to perform a side effect, like creating a database or mocking a module.
You can also run part of a fixture before and part after a test using yield instead of return. For example:
@pytest.fixture
def some_fixture():
# do something before your test
yield # test runs here
# do something after your test
Now, add the following fixture to conftest.py, which creates a new database before each test and removes it after:
import os
import tempfile
import pytest
from blog.models import Article
@pytest.fixture(autouse=True)
def database():
_, file_name = tempfile.mkstemp()
os.environ["DATABASE_NAME"] = file_name
Article.create_table(database_name=file_name)
yield
os.unlink(file_name)
The autouse flag is set to True so that it's automatically used by default before (and after) each test in the test suite. Since we're using a database for all tests it makes sense to use this flag. That way you don't have to explicitly add the fixture name to every test as a parameter.
If you do happen to not need access to the database for a test here and there you can disable
autousewith a test marker. You can see an example of this here.
Run the tests again:
(venv)$ python -m pytest tests
They should pass.
As you can see, our test only tests the CreateArticleCommand command. We don't test the actual Article model since it's not responsible for business logic. We know that the command works as expected. Therefore, there's no need to write any additional tests.
List All Articles
The next requirement is to list all articles. We'll use a query instead of command here, so add a new file called test_queries.py to the "test_article" folder:
from blog.models import Article
from blog.queries import ListArticlesQuery
def test_list_articles():
"""
GIVEN 2 articles stored in the database
WHEN the execute method is called
THEN it should return 2 articles
"""
Article(
author="[email protected]",
title="New Article",
content="Super extra awesome article"
).save()
Article(
author="[email protected]",
title="Another Article",
content="Super awesome article"
).save()
query = ListArticlesQuery()
assert len(query.execute()) == 2
Run the tests:
(venv)$ python -m pytest tests
They should fail.
Add a queries.py file to the "blog" folder:
blog_app
├── blog
│ ├── __init__.py
│ ├── app.py
│ ├── commands.py
│ ├── models.py
│ └── queries.py
└── tests
├── __init__.py
├── conftest.py
├── pytest.ini
└── test_article
├── __init__.py
├── test_commands.py
└── test_queries.py
Now we can implement our query:
from typing import List
from pydantic import BaseModel
from blog.models import Article
class ListArticlesQuery(BaseModel):
def execute(self) -> List[Article]:
articles = Article.list()
return articles
Despite having no parameters here, for consistency we inherited from BaseModel.
Run the tests again:
(venv)$ python -m pytest tests
They should now pass.
Get Article by ID
Getting a single article by its ID can be done in similar way as listing all articles. Add a new test for GetArticleByIDQuery to test_queries.py.:
from blog.models import Article
from blog.queries import ListArticlesQuery, GetArticleByIDQuery
def test_list_articles():
"""
GIVEN 2 articles stored in the database
WHEN the execute method is called
THEN it should return 2 articles
"""
Article(
author="[email protected]",
title="New Article",
content="Super extra awesome article"
).save()
Article(
author="[email protected]",
title="Another Article",
content="Super awesome article"
).save()
query = ListArticlesQuery()
assert len(query.execute()) == 2
def test_get_article_by_id():
"""
GIVEN ID of article stored in the database
WHEN the execute method is called on GetArticleByIDQuery with an ID
THEN it should return the article with the same ID
"""
article = Article(
author="[email protected]",
title="New Article",
content="Super extra awesome article"
).save()
query = GetArticleByIDQuery(
id=article.id
)
assert query.execute().id == article.id
Run the tests to ensure they fail:
(venv)$ python -m pytest tests
Next, add GetArticleByIDQuery to queries.py:
from typing import List
from pydantic import BaseModel
from blog.models import Article
class ListArticlesQuery(BaseModel):
def execute(self) -> List[Article]:
articles = Article.list()
return articles
class GetArticleByIDQuery(BaseModel):
id: str
def execute(self) -> Article:
article = Article.get_by_id(self.id)
return article
The tests should now pass:
(venv)$ python -m pytest tests
Nice. We've meet all of the above mentioned requirements:
- articles can be created
- articles can be fetched
- articles can be listed
And they're all covered with tests. Since we're using pydantic for data validation at runtime, we don't need a lot of tests to cover the business logic as we don't need to write tests for validating data. If author is not a valid email, pydantic will raise an error. All that was needed was to set the author attribute to the EmailStr type. We don't need to test it either because it's already being tested by the pydantic maintainers.
With that, we're ready to expose this functionality to the world via a Flask RESTful API.
Expose the API with Flask
We'll introduce three endpoints that cover this requirement:
/create-article/- create a new article/article-list/- retrieve all articles/article/<article_id>/- fetch a single article
First, create a folder called "schemas" inside "test_article", and add two JSON schemas to it, Article.json and ArticleList.json.
Article.json:
{
"$schema": "http://json-schema.org/draft-07/schema#",
"title": "Article",
"type": "object",
"properties": {
"id": {
"type": "string"
},
"author": {
"type": "string"
},
"title": {
"type": "string"
},
"content": {
"type": "string"
}
},
"required": ["id", "author", "title", "content"]
}
ArticleList.json:
{
"$schema": "http://json-schema.org/draft-07/schema#",
"title": "ArticleList",
"type": "array",
"items": {"$ref": "file:Article.json"}
}
JSON Schemas are used to define the responses from API endpoints. Before continuing, install the jsonschema Python library, which will be used to validate JSON payloads against the defined schemas, and Flask:
(venv)$ pip install jsonschema Flask
Next, let's write integration tests for our API.
Add a new file called test_app.py to "test_article":
import json
import pathlib
import pytest
from jsonschema import validate, RefResolver
from blog.app import app
from blog.models import Article
@pytest.fixture
def client():
app.config["TESTING"] = True
with app.test_client() as client:
yield client
def validate_payload(payload, schema_name):
"""
Validate payload with selected schema
"""
schemas_dir = str(
f"{pathlib.Path(__file__).parent.absolute()}/schemas"
)
schema = json.loads(pathlib.Path(f"{schemas_dir}/{schema_name}").read_text())
validate(
payload,
schema,
resolver=RefResolver(
"file://" + str(pathlib.Path(f"{schemas_dir}/{schema_name}").absolute()),
schema # it's used to resolve the file inside schemas correctly
)
)
def test_create_article(client):
"""
GIVEN request data for new article
WHEN endpoint /create-article/ is called
THEN it should return Article in json format that matches the schema
"""
data = {
'author': "[email protected]",
"title": "New Article",
"content": "Some extra awesome content"
}
response = client.post(
"/create-article/",
data=json.dumps(
data
),
content_type="application/json",
)
validate_payload(response.json, "Article.json")
def test_get_article(client):
"""
GIVEN ID of article stored in the database
WHEN endpoint /article/<id-of-article>/ is called
THEN it should return Article in json format that matches the schema
"""
article = Article(
author="[email protected]",
title="New Article",
content="Super extra awesome article"
).save()
response = client.get(
f"/article/{article.id}/",
content_type="application/json",
)
validate_payload(response.json, "Article.json")
def test_list_articles(client):
"""
GIVEN articles stored in the database
WHEN endpoint /article-list/ is called
THEN it should return list of Article in json format that matches the schema
"""
Article(
author="[email protected]",
title="New Article",
content="Super extra awesome article"
).save()
response = client.get(
"/article-list/",
content_type="application/json",
)
validate_payload(response.json, "ArticleList.json")
So, what's happening here?
- First, we defined the Flask test client as a fixture so that it can be used in the tests.
- Next, we added a function for validating payloads. It takes two parameters:
payload- JSON response from the APIschema_name- name of the schema file inside the "schemas" directory
- Finally, there are three tests, one for each endpoint. Inside each test there's a call to the API and validation of the returned payload
Run the tests to ensure they fail at this point:
(venv)$ python -m pytest tests
Now we can write the API.
Update app.py like so:
from flask import Flask, jsonify, request
from blog.commands import CreateArticleCommand
from blog.queries import GetArticleByIDQuery, ListArticlesQuery
app = Flask(__name__)
@app.route("/create-article/", methods=["POST"])
def create_article():
cmd = CreateArticleCommand(
**request.json
)
return jsonify(cmd.execute().dict())
@app.route("/article/<article_id>/", methods=["GET"])
def get_article(article_id):
query = GetArticleByIDQuery(
id=article_id
)
return jsonify(query.execute().dict())
@app.route("/article-list/", methods=["GET"])
def list_articles():
query = ListArticlesQuery()
records = [record.dict() for record in query.execute()]
return jsonify(records)
if __name__ == "__main__":
app.run()
Our route handlers are pretty simple since all of our logic is covered by the commands and queries. Available actions with side effects (like mutations) are represented by commands -- e.g., creating a new article. On the other hand, actions that don't have side effects, the ones that are just reading current state, are covered by queries.
The command and query pattern used in this post is a simplified version of the CQRS pattern. We're combining CQRS and CRUD.
The
.dict()method above is provided by theBaseModelfrom pydantic, which all of our models inherit from.
The tests should pass:
(venv)$ python -m pytest tests
We've covered the happy path scenarios. In the real world we must expect that clients won't always use the API as it was intended. For example, when a request to create an article is made without a title, a ValidationError will be raised by the CreateArticleCommand command, which will result in an internal server error and an HTTP status 500. That's something that we want to avoid. Therefore, we need to handle such errors to notify the user about the bad request gracefully.
Let's write tests to cover such cases. Add the following to test_app.py:
@pytest.mark.parametrize(
"data",
[
{
"author": "John Doe",
"title": "New Article",
"content": "Some extra awesome content"
},
{
"author": "John Doe",
"title": "New Article",
},
{
"author": "John Doe",
"title": None,
"content": "Some extra awesome content"
}
]
)
def test_create_article_bad_request(client, data):
"""
GIVEN request data with invalid values or missing attributes
WHEN endpoint /create-article/ is called
THEN it should return status 400
"""
response = client.post(
"/create-article/",
data=json.dumps(
data
),
content_type="application/json",
)
assert response.status_code == 400
assert response.json is not None
We used pytest's parametrize option, which simplifies passing in multiple inputs to a single test.
Test should fail at this point because we haven't handled the ValidationError yet:
(venv)$ python -m pytest tests
So let's add an error handler to the Flask app inside app.py:
from pydantic import ValidationError
# Other code ...
app = Flask(__name__)
@app.errorhandler(ValidationError)
def handle_validation_exception(error):
response = jsonify(error.errors())
response.status_code = 400
return response
# Other code ...
ValidationError has an errors method that returns a list of all errors for each field that was either missing or passed a value that didn't pass validation. We can simply return this in the body and set the response's status to 400.
Now that the error is handled appropriately all tests should pass:
(venv)$ python -m pytest tests
Code Coverage
Now, with our application tested, it's the time to check code coverage. So let's install a pytest plugin for coverage called pytest-cov:
(venv)$ pip install pytest-cov
After the plugin is installed, we can check code coverage of our blog application like this:
(venv)$ python -m pytest tests --cov=blog
You should see something similar to:
---------- coverage: platform darwin, python 3.10.1-final-0 ----------
Name Stmts Miss Cover
--------------------------------------
blog/__init__.py 0 0 100%
blog/app.py 25 1 96%
blog/commands.py 16 0 100%
blog/models.py 57 1 98%
blog/queries.py 12 0 100%
--------------------------------------
TOTAL 110 2 98%
Is 98% coverage good enough? It probably is. Nonetheless, remember one thing: High coverage percentage is great but the quality of your tests is much more important. If only 70% or less of code is covered you should think about increasing coverage percentage. But it generally doesn't make sense to write tests to go from 98% to 100%. (Again, tests need to be maintained just like your business logic!)
End-to-end Tests
We have a working API at this point that's fully tested. We can now look at how to write some end-to-end (e2e) tests. Since we have a simple API we can write a single e2e test to cover the following scenario:
- create a new article
- list articles
- get the first article from the list
First, install the requests library:
(venv)$ pip install requests
Second, add a new test to test_app.py:
import requests
# other code ...
@pytest.mark.e2e
def test_create_list_get(client):
requests.post(
"http://localhost:5000/create-article/",
json={
"author": "[email protected]",
"title": "New Article",
"content": "Some extra awesome content"
}
)
response = requests.get(
"http://localhost:5000/article-list/",
)
articles = response.json()
response = requests.get(
f"http://localhost:5000/article/{articles[0]['id']}/",
)
assert response.status_code == 200
There are two things that we need to do before running this test...
First, register a marker called e2e with pytest by adding the following code to pytest.ini:
[pytest]
markers =
e2e: marks tests as e2e (deselect with '-m "not e2e"')
pytest markers are used to exclude some tests from running or to include selected tests independent of their location.
To run only the e2e tests, run:
(venv)$ python -m pytest tests -m 'e2e'
To run all tests except e2e:
(venv)$ python -m pytest tests -m 'not e2e'
e2e tests are more expensive to run and require the app to be up and running, so you probably don't want to run them at all times.
Since our e2e test hits a live server, we'll need to spin up the app. Navigate to the project in a new terminal window, activate the virtual environment, and run the app:
(venv)$ FLASK_APP=blog/app.py python -m flask run
Now we can run our e2e test:
(venv)$ python -m pytest tests -m 'e2e'
You should see a 500 error. Why? Don't the unit tests pass? Yes. The problem is that we didn't create the database table. We used fixtures for this in our tests which do this for us. So let's create a table and a database.
Add an init_db.py file to the "blog" folder:
if __name__ == "__main__":
from blog.models import Article
Article.create_table()
Run the new script and start the server again:
(venv)$ python blog/init_db.py
(venv)$ FLASK_APP=blog/app.py python -m flask run
If you run into any problems running init_db.py, you may need to set the Python path:
export PYTHONPATH=$PYTHONPATH:$PWD.
The test should now pass:
(venv)$ python -m pytest tests -m 'e2e'
Testing Pyramid
We started with unit tests (to test the commands and queries) followed by integration tests (to test the API endpoints), and finished with e2e tests. In simple applications, as in this example, you may end up with a similar number of unit and integration tests. In general, the greater the complexity, the more you should see a pyramid-like shape in terms of the relationship between unit, integration, and e2e tests. That's where the "test pyramid" term comes from.
The Test Pyramid is a framework that can help developers create high-quality software.
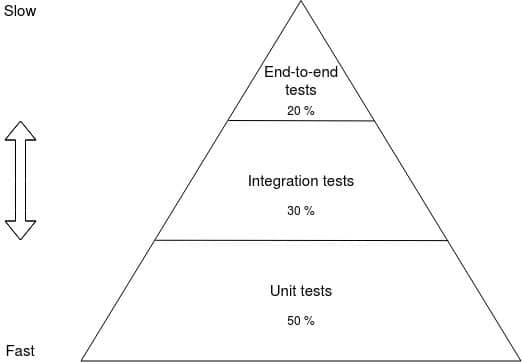
Using the Test Pyramid as a guide, you typically want 50% of your tests in your test suite to be unit tests, 30% to be integration tests, and 20% to be e2e tests.
Definitions:
- Unit test - tests a single unit of code
- Integration tests - tests that multiple units work together
- e2e - tests the whole application against a live production-like server
The higher up you go in the pyramid, the more brittle and less predictable your tests are. What's more, e2e tests are by far the slowest to run so even though they can bring confidence that your application is doing what's expected of it, you shouldn't have nearly as many of them as unit or integration tests.
What is a Unit?
It's pretty straightforward what integration and e2e tests look like. There's much more discussion about unit tests since you first have to define what a "unit" actually is. Most testing tutorials show a unit test example that tests a single function or method. Production code is never that simple.
First things first, before defining what a unit is, let's look at what the point of testing is in general and what should be tested.
Why Test?
We write tests to:
- Ensure our code works as expected
- Protect our software against regressions
Nonetheless, when feedback cycles are too long, developers tend to start to think more about the types of tests to write since time is a major constraint in software development. That's why we want to have more unit tests than other types of tests. We want to find and fix the defect as fast as possible.
What to Test?
Now that you know why we should test, we now must look at what we should test.
We should test the behavior of our software. (And, yes: This still applies to TDD, not just BDD.) This is because you shouldn't have to change your tests every time there's a change to the code base.
Think back to the example of the real world application. From a testing perspective, we don't care where the articles are stored. It could be a text file, some other relational database, or a key/value store -- it doesn't matter. Again, our app had the following requirements:
- articles can be created
- articles can be fetched
- articles can be listed
As long as those requirements don't change, a change to the storage medium shouldn't break our tests. Similarly, we know that as long as those tests pass, we know our software meets those requirements -- so it's working.
So What is a Unit Then?
Each function/method is technically a unit, but we still shouldn't test every single one of them. Instead, focus your energy on testing the functions and methods that are publicly exposed from a module/package.
In our case, these were the execute methods. We don't expect to call the Article model directly from the Flask API, so don't focus much (if any) energy on testing it. To be more precise, in our case, the "units", that should be tested, are the execute methods from the commands and queries. If some method is not intended to be directly called from other parts of our software or an end user, it's probably implementation detail. Consequently, our tests are resistant to refactoring to the implementation details, which is one of the qualities of great tests.
For example, our tests should still pass if we wrapped the logic for get_by_id and get_by_title in a "protected" method called _get_by_attribute:
# other code ...
class Article(BaseModel):
id: str = Field(default_factory=lambda: str(uuid.uuid4()))
author: EmailStr
title: str
content: str
@classmethod
def get_by_id(cls, article_id: str):
return cls._get_by_attribute("SELECT * FROM articles WHERE id=?", (article_id,))
@classmethod
def get_by_title(cls, title: str):
return cls._get_by_attribute("SELECT * FROM articles WHERE title = ?", (title,))
@classmethod
def _get_by_attribute(cls, sql_query: str, sql_query_values: tuple):
con = sqlite3.connect(os.getenv("DATABASE_NAME", "database.db"))
con.row_factory = sqlite3.Row
cur = con.cursor()
cur.execute(sql_query, sql_query_values)
record = cur.fetchone()
if record is None:
raise NotFound
article = cls(**record) # Row can be unpacked as dict
con.close()
return article
# other code ..
On the other hand, if you make a breaking change inside Article the tests will fail. And that's exactly what we want. In that situation, we can either revert the breaking change or adapt to it inside our command or query.
Because there's one thing that we're striving for: Passing tests means working software.
When Should You Use Mocks?
We didn't use any mocks in our tests, because we didn't need them. Mocking methods or classes inside your modules or packages produces tests that are not resistant to refactoring because they are coupled to the implementation details. Such tests break often and are costly to maintain. On the other hand, it makes sense to mock external resources when speed is an issue (calls to external APIs, sending emails, long-running async processes, etc.).
For example, we could test the Article model separately and mock it inside our tests for CreateArticleCommand like so:
def test_create_article(monkeypatch):
"""
GIVEN CreateArticleCommand with valid properties author, title and content
WHEN the execute method is called
THEN a new Article must exist in the database with same attributes
"""
article = Article(
author="[email protected]",
title="New Article",
content="Super awesome article"
)
monkeypatch.setattr(
Article,
"save",
lambda self: article
)
cmd = CreateArticleCommand(
author="[email protected]",
title="New Article",
content="Super awesome article"
)
db_article = cmd.execute()
assert db_article.id == article.id
assert db_article.author == article.author
assert db_article.title == article.title
assert db_article.content == article.content
Yes, that's perfectly fine to do, but we now have more tests to maintain -- i.e., all the tests from before plus all the new tests for the methods in Article. Besides that, the only thing that's now tested by test_create_article is that an article returned from save is the same as the one returned by execute. When we break something inside Article this test will still pass because we mocked it. And that's something we want to avoid: We want to test software behavior to ensure that it works as expected. In this case, behavior is broken but our test won't show that.
Takeaways
- There's no single right way to test your software. Nonetheless, it's easier to test logic when it's not coupled with your database. You can use the Active Record pattern with commands and queries (CQRS) to help with this.
- Focus on the business value of your code.
- Don't test methods just to say they're tested. You need working software not tested methods. TDD is just a tool to deliver better software faster and more reliable. Similar can be said for code coverage: Try to keep it high but don't add tests just to have 100% coverage.
- A test is valuable only when it protects you against regressions, allows you to refactor, and provides you fast feedback. Therefore, you should strive for your tests to resemble a pyramid shape (50% unit, 30% integration, 20% e2e). Although, in simple applications, it may look more like a house (40% unit, 40% integration, 20% e2e), which is fine.
- The faster you notice regressions, the faster you can intercept and correct them. The faster you correct them, the shorter the development cycle. To speed up feedback, you can use pytest markers to exclude e2e and other slow tests during development. You can run them less frequently.
- Use mocks only when necessary (like for third-party HTTP APIs). They make your test setup more complicated and your tests overall less resistant to refactoring. Plus, they can result in false positives.
- Once again, your tests are a liability not an asset; they should cover your software's behavior but don't over test.
Conclusion
There's a lot to digest here. Keep in mind that these are just examples used to show the ideas. You can use the same ideas with Domain-driven design (DDD), Behavior-driven design (BDD), and many other approaches. Keep in mind that tests should be treated the same as any other code: They are a liability and not an asset. Write tests to protect your software against the bugs but don't let it burn your time.
Want to learn more?
- TDD - Where did it all go wrong?
- TDD with Python
- A Pytest pattern: using "parametrize" to customise nested fixtures
The Complete Python Guide: