 Jan Giacomelli
Jan Giacomelli
Python 3.9, which was released on October 5th 2020, doesn't bring any major new features to the table, but there are still some significant changes especially to how the language is developed and released.
Contents
Development Cycle
This is the first Python release coming from the new release philosophy, where major releases happen every 12-months (in October) rather than every 18-months. With releases being more frequent, changes should be smaller -- which is exactly what we're seeing in Python 3.9.
All new versions have 1.5 years of full support along with 3.5 years of security fixes.
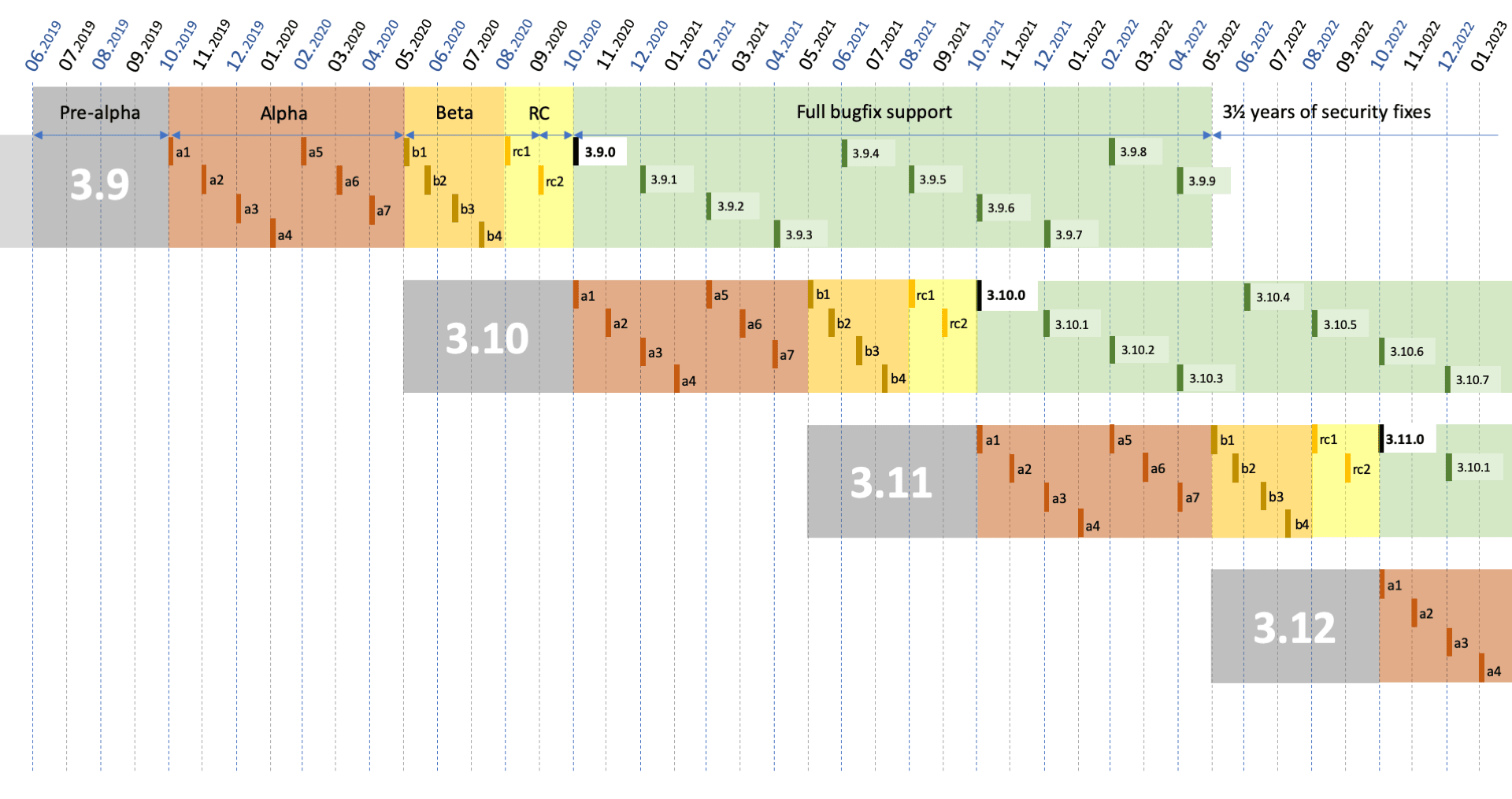
More info: https://www.python.org/dev/peps/pep-0602/
Dictionary Unions
Merge dictionaries
We now have a merge operator for performing dictionary unions: |. It works the same as a.update(b) or {**a, **b}, with one difference: It works for any instance of the dict subclass.
If you have Docker, you can quickly spin up a Python 3.9 shell to play around with the examples in this post via:
docker run -it --rm python:3.9.
You can merge two dictionaries like so:
user = {'name': 'John', 'surname': 'Doe'}
address = {'street': 'Awesome street 42', 'city': 'Huge city', 'post': '420000'}
user_with_address = user | address
print(user_with_address)
# {'name': 'John', 'surname': 'Doe', 'street': 'Awesome street 42', 'city': 'Huge city', 'post': '420000'}
Now, we have a new dictionary called user_with_address, which is a union of user and address.
If there are duplicate keys in the dictionaries, then the output will display the second (rightmost) key-value pair:
user_1 = {'name': 'John', 'surname': 'Doe'}
user_2 = {'name': 'Joe', 'surname': 'Doe'}
users = user_1 | user_2
print(users)
# {'name': 'Joe', 'surname': 'Doe'}
|operator means union, not or. It doesn't do any bitwise work nor does it serve as logical operator. It's used to create a union of two dictionaries. Since it looks similar to an or condition in other languages, you may want to double check how it's being used during code reviews.
Updating dictionaries
As for updating, you now have the operator |=. This works in place.
You can update the first dictionary with keys and values from the second like so:
grades = {'John': 'A', 'Marry': 'B+'}
grades_second_try = {'Marry': 'A', 'Jane': 'C-', 'James': 'B'}
grades |= grades_second_try
print(grades)
# {'John': 'A', 'Marry': 'A', 'Jane': 'C-', 'James': 'B'}
It works for anything with keys and __getitem__ or iterables with key-value pairs:
# example 1
grades = {'John': 'A', 'Marry': 'B+'}
grades_second_try = [('Marry', 'A'), ('Jane', 'C-'), ('James', 'B')]
grades |= grades_second_try
print(grades)
# {'John': 'A', 'Marry': 'A', 'Jane': 'C-', 'James': 'B'}
# example 2
x = {0: 0, 1: 1}
y = ((i, i**2) for i in range(2,6))
x |= y
print(x)
{0: 0, 1: 1, 2: 4, 3: 9, 4: 16, 5: 25}
# example 3
x | y
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unsupported operand type(s) for |: 'dict' and 'generator'
More info: https://www.python.org/dev/peps/pep-0584/
Generating Random Bytes
The random library can now be used to generate random bytes via randbytes.
For example, to generate ten random bytes:
import random
print(random.Random().randbytes(10))
b'CO\x0e\x0e~\x12\x0c\xa4\xa0p'
More info: https://bugs.python.org/issue40286
String Methods
Two methods were added to the str object:
removeprefix
This first method removes the inputted string from the beginning of another string.
For example:
file_name = 'DOCUMENT_001.pdf'
print(file_name.removeprefix('DOCUMENT_'))
# 001.pdf
If the string doesn't start with the input string, a copy of the original string will be returned:
file_name = 'DOCUMENT_001.pdf'
print(file_name.removeprefix('DOC_'))
# DOCUMENT_001.pdf
removesuffix
Similarly, we can remove the suffix from the selected string with the second method.
To remove the .pdf file extension from the file name:
file_name = 'DOCUMENT_001.pdf'
print(file_name.removesuffix('.pdf'))
# DOCUMENT_001
file_name = 'DOCUMENT_001.pdf'
print(file_name.removesuffix('.csv'))
# DOCUMENT_001.pdf
More info: https://www.python.org/dev/peps/pep-0616/
IANA Timezone Support
The zoneinfo module has been added to support the IANA time zone database.
For example, to create a time zone–aware timestamp, you can add the tz or tzinfo arguments to the datetime method:
import datetime
from zoneinfo import ZoneInfo
datetime.datetime(2020, 10, 7, 1, tzinfo=ZoneInfo('America/Los_Angeles'))
# datetime.datetime(2020, 10, 7, 1, 0, tzinfo=zoneinfo.ZoneInfo(key='America/Los_Angeles'))
You can easily convert between time zones as well:
import datetime
from zoneinfo import ZoneInfo
start = datetime.datetime(2020, 10, 7, 1, tzinfo=ZoneInfo('America/Los_Angeles'))
start.astimezone(ZoneInfo('Europe/London'))
datetime.datetime(2020, 10, 7, 9, 0, tzinfo=zoneinfo.ZoneInfo(key='Europe/London'))
More info: https://www.python.org/dev/peps/pep-0615/
Generic Type Annotations
From now on you can use generic types for type annotations. Instead of having to use typing.List or typing.Dict, you can use the list or dict built-in collection types as generic types
def sort_names(names: list[str]):
return sorted(names)
With Python being dynamically typed, types are dynamically inferred. Since this isn't always desireable, type hinting can be used to specify types. This was introduced way back in Python 3.5. Being able to use built-in collection types as generic types greatly simplifies type hinting.
More info: https://www.python.org/dev/peps/pep-0585/
Canceling Concurrent Futures
A new parameter called cancel_futures has been added to concurrent.futures.Executor.shutdown(). When set to True, it cancels all pending futures that have not started running. Prior to version 3.9, the process would wait for them to complete before shutting down the executor.
More info: https://bugs.python.org/issue30966
ImportError
In previous versions __import__ and importlib.util.resolve_name() raised ValueError when relative import went past its top-level package. Now you'll get an ImportError, which better describes the condition being handled.
More info: https://bugs.python.org/issue37444
String Replace Fix
An issue with string replace for empty strings has been fixed.
In previous versions:
"".replace("", "prefix", 1)
# ''
From now on:
"".replace("", "prefix", 1)
# 'prefix'
More info: https://bugs.python.org/issue28029
New Parser
A new, more flexible, parser based on PEG (Parsing expression grammar) has been introduced. Although you probably won't notice it, this is the most significant change for this release of Python.
The PEG-based parser's performance is comparable to the old old LL(1) (Left-to-right parser) but it's more flexible formalism should make it easier to design new language features.
More info: https://www.python.org/dev/peps/pep-0617
Performance
Finally, the vectorcall protocol, which was introduced in Python 3.8, has now been extended to several built-ins, including range, tuple, set, frozenset, list, and dict. In short, vectorcall makes many common function calls faster by removing the overhead from reducing the number of temporary objects created for the call.
More info: https://docs.python.org/3.9/c-api/call.html#the-vectorcall-protocol
Conclusion
This post touched on just the major changes to the language. A full list of changes can be found here.
Happy coding!