Django REST Framework's ModelViewSet
Django REST Framework tip:
If your API endpoints map close to your models, you can save yourself quite a few lines of code by using ModelViewSet in combination with a router.
# viewsets.py class PostModelViewSet(ModelViewSet): serializer_class = PostSerializer queryset = Post.objects.all() # urls.py router = routers.DefaultRouter() router.register(r'', PostModelViewSet) urlpatterns = [ path('', include(router.urls)), ] # yields: http://127.0.0.1:8000/ # for list of posts http://127.0.0.1:8000/1/ # for post detail(ViewSets should be stored in a file named viewsets.py rather than views.py.)
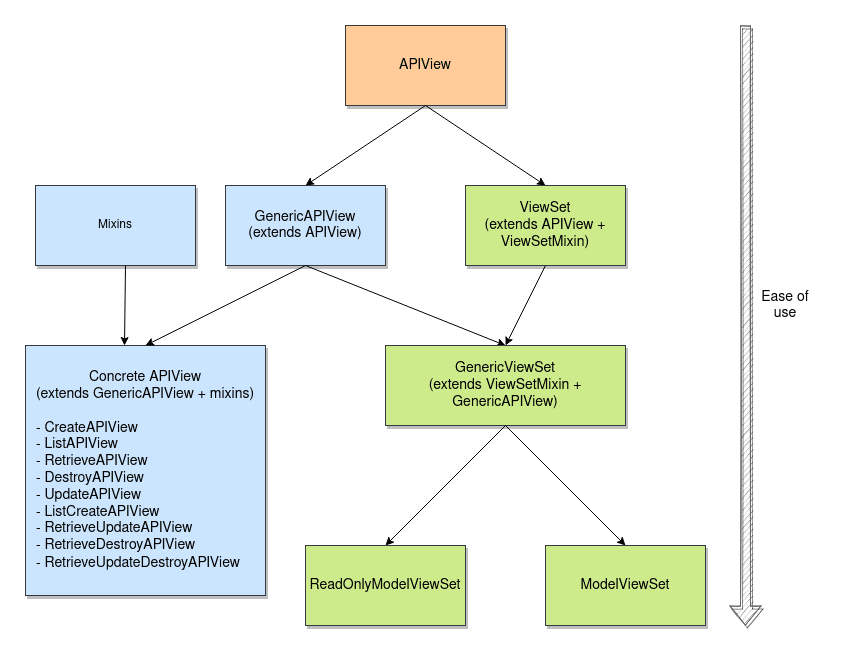
How to create views in Django REST Framework
Django REST Framework tip:
There are three core ways to create views:
- extending APIView class
- Extending one of the seven concrete API views (e.g.,
ListCreateAPIView)- ViewSet (e.g., ModelViewSet)
There are also some sub-possibilities:
Django's length template filter
Django tip:
If you want to show the length of a string or list, you can use the length template filter.
{{ friends|length }}
Django's pluralize template filter
Django tip:
Sometimes you need to use the single or plural form based on the number you're displaying. You can handle this by using the pluralize filter.
{{ number_of_friends }} friend{{ number_of_friends|pluralize }} # 1 friend # 2 friendsAn "s" is automatically used as the suffix, but you can also provide your own suffix (for both singular and plural versions).
{{ number_of_mice }} {{ number_of_mice|pluralize:"mouse,mice" }} # 1 mouse # 2 mice
Selecting a random element from a list in a Django template
Django tip:
You can use the random Django template filter to return a random item from the given list.
{{ inspirational_quote|random }}
Slicing a list in a Django template
Django tip:
You can return only part of the list in a Django template by using the slice filter.
The syntax for slicing is the same as for Python’s list slicing.
{{ friends|slice:":3" }}
Django Date Template Filter
Django tip:
You can use the date filter to format a given date/time.
Example:
{{ post.datetime|date:"jS F Y" }} # => 1st January 2022After the colon, you can provide the desired format inside the string. If the format is not provided, the filter will use the default one, which can be specified in the settings.
Convert letter case in a Django template
Django tip:
There are four template filters you can use to change letter case:
{{ item.name|title }} {{ item.name|capfirst }} {{ item.name|lower }} {{ item.name|upper }}
Check if a For Loop Variable Is Empty in a Django Template
Django tip:
When looping through a list in a Django template, you can use the empty tag to cover cases when the list is empty:
{% for item in list %} {{ item }} {% empty %} <p>There are no items yet.</p> {% endfor %}
Create Custom Django Admin Actions
Django tip:
You can create custom bulk actions for the Django admin.
Example:
@admin.action(description='Mark selected items purchased') def make_purchased(modeladmin, request, queryset): queryset.update(purchased=True) @admin.register(ShoppingItem) class ShoppingItemAdmin(admin.ModelAdmin): actions = [make_purchased]
How to exclude Django Modelform fields
Django tip:
You can use either
excludeorfieldsto impact which fields will be available in the Django admin model forms.For example:
# models.py class Child(models.Model): name = models.CharField(max_length=200) last_name = models.CharField(max_length=200) grade = models.CharField(max_length=200) # admin.py @admin.register(Child) class ChildAdmin(admin.ModelAdmin): exclude = ('grade',) # yields the same result as @admin.register(Child) class ChildAdmin(admin.ModelAdmin): fields = ('name', 'last_name')
How to check for first or last iteration of a for loop in a Django template
Django tip:
You can use
forloop.firstorforloop.lastto check if the current iteration is the first or the last time through a for loop in your Django templates like so:{% for item in item_list %} {{ forloop.first }} # True if this is the first time through the loop {{ forloop.last }} # True if this is the last time through the loop {% endfor %}
Current iteration from the end of a for loop in a Django template - forloop.revcounter
Django tip:
You can use
revcounterto get the number of iterations from the end of a for loop in your Django templates like so:{% for item in item_list %} {{ forloop.revcounter }} # starting index 1 {{ forloop.revcounter0 }} # starting index 0 {% endfor %}
Current iteration of a for loop in a Django template - forloop.counter
Django tip:
You can use
counterto get the current iteration of a for loop in your Django templates like so:{% for item in item_list %} {{ forloop.counter }} # starting index 1 {{ forloop.counter0 }} # starting index 0 {% endfor %}
Django - Custom verbose plural name for admin model class
Django tip:
Django automatically creates a plural verbose name from your object by adding and "s" to the end.
child -> childs
To change the plural verbose name, you can define the verbose_name_plural property of the Meta class like so:
class Child(models.Model): ... class Meta: verbose_name_plural = "children"
Django - Custom Database Constraints
Django tip:
You can add custom database constraints to your Django models like so:
class Child(models.Model): .... class Meta: constraints = [ models.CheckConstraint(check=models.Q(age__lt=18)) ]
Custom Django Management Commands
Django tip:
You can create your own custom Django management commands that you can run with manage.py. For example:
python manage.py your_commandSimply add a Python module to a "management/commands" folder in a Django app.
Example:
your_app/ __init__.py models.py management/ __init__.py commands/ __init__.py your_command.py tests.py views.py(Django will ignore any module that begins with an underscore.)
Example command:
from django.core.management.base import BaseCommand class Command(BaseCommand): def handle(self, *args, **options): self.stdout.write('pong!')
Django Admin - custom filters with list_filter
Django tip:
With list_filter you can add custom filters to the right sidebar of the Django admin list page.
For example:
@admin.register(Child) class ItemAdmin(admin.ModelAdmin): list_filter = ("grade", )
Django - reference method in the list_display tuple for the admin
Django tip:
Besides model fields, the
list_displaytuple can reference methods fromModelAdmin:@admin.register(ShoppingList) class ShoppingListAdmin(admin.ModelAdmin): list_display = ("title", "number_of_items") def number_of_items(self, obj): result = ShoppingItem.objects.filter(shopping_list=obj.id).count() return result
Customize the Django admin with list_display
Django tip:
You can make your admin list page friendlier to the user by specifying which fields should be displayed:
@admin.register(Child) class ChildAdmin(admin.ModelAdmin): list_display = ("last_name", "first_name")
Custom field for search in the Django admin
Django tip:
search_fields sets which model fields will be searched when a search is performed in the Django admin.
You can also perform a related lookup on a ForeignKey or ManyToManyField with the lookup API "follow" notation (double underscore syntax):
@admin.register(Child) class ChildAdmin(admin.ModelAdmin): search_fields = ['parent__name']
Registering models with the Django Admin
Django tip:
Instead of using
admin.site.registerfor registering models with the Django admin, you can use a decorator.https://docs.djangoproject.com/en/4.0/ref/contrib/admin/#the-register-decorator
👇
## option 1 ## class AuthorAdmin(admin.ModelAdmin): fields = ('name', 'title') admin.site.register(Author, AuthorAdmin) ## option 2 ## # you can use a decorator instead @admin.register(Author) class AuthorAdmin(admin.ModelAdmin): fields = ('name', 'title')
Testing tip - focus testing efforts on testing private methods
Testing tip:
Focus the majority of your testing efforts on testing methods that you (or other stakeholders) intend to call from other packages/modules. Everything else is just an implementation detail.
Testing tip - use mocks only when necessary
Testing tip:
Use mocks only when necessary (like for third-party HTTP APIs). They make your test setup more complicated and your tests overall less resistant to refactoring.
Plus, they can result in false positives.
Shorten development cycles with pytest markers
Testing tip:
The faster you notice regressions, the faster you can intercept and correct them. The faster you correct them, the shorter the development cycle.
You can use pytest markers to exclude e2e and other slow tests during development. You can run them less frequently.
Writing Valuable Tests
Testing tip:
A test is valuable only when it protects you against regressions, allows you to refactor, and provides you with fast feedback.
Testing tip - create more loosely coupled components and modules
Testing tip:
There's no single right way to test your software.
Nonetheless, it's easier and faster to test logic when it's not coupled with your database.
Python Testing - Mocking different responses for consecutive calls
Python testing tip:
You can specify different responses for consecutive calls to your
MagicMock.It's useful when you want to mock a paginated response.
👇
from unittest.mock import MagicMock def test_all_cars_are_fetched(): get_cars_mock = MagicMock() get_cars_mock.side_effect = [ ["Audi A3", "Renault Megane"], ["Nissan Micra", "Seat Arona"] ] print(get_cars_mock()) # ['Audi A3', 'Renault Megane'] print(get_cars_mock()) # ['Nissan Micra', 'Seat Arona']
Type Hints - How to Use typing.cast() in Python
Python tip:
You can use
cast()to signal to a type checker that the value has a designated type.https://docs.python.org/3/library/typing.html#typing.cast
👇
from dataclasses import dataclass from enum import Enum from typing import cast class BoatStatus(int, Enum): RESERVED = 1 FREE = 2 @dataclass class Boat: status: BoatStatus Boat(status=2) # example.py:16: error: Argument "status" to "Boat" has incompatible type "int"; expected "BoatStatus" # Found 1 error in 1 file (checked 1 source file) Boat(status=cast(BoatStatus, 2))
SQLAlchemy with_for_update
SQLAlchemy tip:
You can use
with_for_update()to use SELECT FOR UPDATE. This will prevent changes in selected rows before you commit your work to the database.https://docs.sqlalchemy.org/en/14/orm/query.html#sqlalchemy.orm.Query.with_for_update
👇
user = session.query(User).filter(User.email == email).with_for_update().first() user.is_active = True session.add(user) session.commit()
Mount a Flask or Django app inside a FastAPI application
FastAPI tip:
You can use
WSGIMiddlewareto mount WSGI applications (like Flask and Django) to your FastAPI API.https://fastapi.tiangolo.com/advanced/wsgi/
👇
from fastapi import FastAPI from fastapi.middleware.wsgi import WSGIMiddleware from flask import Flask, escape, request flask_app = Flask(__name__) @flask_app.route("/") def flask_main(): name = request.args.get("name", "World") return f"Hello, {escape(name)} from Flask!" app = FastAPI() @app.get("/v2") def read_main(): return {"message": "Hello World"} app.mount("/v1", WSGIMiddleware(flask_app))
FastAPI - disable OpenAPI docs
FastAPI tip:
You can disable OpenAPI docs by setting
openapi_urlto an empty string.👇
from fastapi import FastAPI from pydantic import BaseSettings class Settings(BaseSettings): openapi_url: str = "" settings = Settings() app = FastAPI(openapi_url=settings.openapi_url) @app.get("/") def root(): return {"message": "Hello World"}
FastAPI - custom Request and APIRoute class
FastAPI tip:
You can implement custom
RequestandAPIRouteclasses.https://fastapi.tiangolo.com/advanced/custom-request-and-route/
For example, to manipulate the request body before it's processed by your application👇
import gzip from typing import Callable, List from fastapi import Body, FastAPI, Request, Response from fastapi.routing import APIRoute class GzipRequest(Request): async def body(self) -> bytes: if not hasattr(self, "_body"): body = await super().body() if "gzip" in self.headers.getlist("Content-Encoding"): body = gzip.decompress(body) self._body = body return self._body class GzipRoute(APIRoute): def get_route_handler(self) -> Callable: original_route_handler = super().get_route_handler() async def custom_route_handler(request: Request) -> Response: request = GzipRequest(request.scope, request.receive) return await original_route_handler(request) return custom_route_handler app = FastAPI() app.router.route_class = GzipRoute @app.post("/sum") async def sum_numbers(numbers: List[int] = Body(...)): return {"sum": sum(numbers)}
FastAPI - GraphQL with Strawberry
FastAPI tip:
You can use Strawberry to build a GraphQL API with FastAPI.
🍓
https://fastapi.tiangolo.com/fr/advanced/graphql/#graphql-with-strawberry
👇
import strawberry from fastapi import FastAPI from strawberry.asgi import GraphQL @strawberry.type class User: name: str age: int @strawberry.type class Query: @strawberry.field def user(self) -> User: return User(name="Patrick", age=100) schema = strawberry.Schema(query=Query) graphql_app = GraphQL(schema) app = FastAPI() app.add_route("/graphql", graphql_app) app.add_websocket_route("/graphql", graphql_app)
FastAPI - Templates with Jinja2
FastAPI tip:
You can use Jinja2 as a template engine to serve HTML responses from your FastAPI application.
👇
from fastapi import FastAPI, Request from fastapi.responses import HTMLResponse from fastapi.staticfiles import StaticFiles from fastapi.templating import Jinja2Templates app = FastAPI() app.mount("/static", StaticFiles(directory="static"), name="static") templates = Jinja2Templates(directory="templates") @app.get("/items/{id}", response_class=HTMLResponse) async def read_item(request: Request, id: str): return templates.TemplateResponse("item.html", {"request": request, "id": id})
FastAPI Sub Applications
FastAPI tip:
You can use sub-applications when you need two separate OpenAPI schemas and Swagger UIs.
https://fastapi.tiangolo.com/advanced/sub-applications/
You can mount one or many sub-applications.
👇
from fastapi import FastAPI app = FastAPI() @app.get("/app") def read_main(): return {"message": "Hello World from main app"} subapi = FastAPI() @subapi.get("/sub") def read_sub(): return {"message": "Hello World from sub API"} app.mount("/subapi", subapi)
FastAPI shutdown events
FastAPI tip:
You can register functions to run before the application shutdown using
@app.on_event("shutdown").https://fastapi.tiangolo.com/advanced/events/#shutdown-event
For example. to send a message to an SNS topic where you track your app health 👇
import boto3 from fastapi import FastAPI app = FastAPI() @app.on_event("shutdown") def publish_message(): client = boto3.client('sns') client.publish( TopicArn='arn:aws:sns:us-east-1:12345678910112:application-health', Message='Application is shutting down', ) @app.get("/ping") async def ping(): return {"message": "pong"}
FastAPI startup events
FastAPI tip:
You can register functions to run before the application start using
@app.on_event("startup").https://fastapi.tiangolo.com/advanced/events/#startup-event
For example, to send a message to an AWS SNS topic where you track your app health:
import boto3 from fastapi import FastAPI app = FastAPI() @app.on_event("startup") def publish_message(): client = boto3.client('sns') client.publish( TopicArn='arn:aws:sns:us-east-1:12345678910112:application-health', Message='Application is starting', ) @app.get("/ping") async def ping(): return {"message": "pong"}
FastAPI WebSockets
FastAPI tip:
You can easily add WebSockets to your app with
@app.websocket().https://fastapi.tiangolo.com/advanced/websockets/
👇
from fastapi import FastAPI, WebSocket from fastapi.responses import HTMLResponse app = FastAPI() html = """ <!DOCTYPE html> <html> <head> <title>Chat</title> </head> <body> <h1>WebSocket Chat</h1> <form action="" onsubmit="sendMessage(event)"> <input type="text" id="messageText" autocomplete="off"/> <button>Send</button> </form> <ul id='messages'> </ul> <script> var ws = new WebSocket("ws://localhost:8000/ws"); ws.onmessage = function(event) { var messages = document.getElementById('messages') var message = document.createElement('li') var content = document.createTextNode(event.data) message.appendChild(content) messages.appendChild(message) }; function sendMessage(event) { var input = document.getElementById("messageText") ws.send(input.value) input.value = '' event.preventDefault() } </script> </body> </html> """ @app.get("/") async def get(): return HTMLResponse(html) @app.websocket("/ws") async def websocket_endpoint(websocket: WebSocket): await websocket.accept() while True: data = await websocket.receive_text() await websocket.send_text(f"Message text was: {data}")
FastAPI - Using alias parameters to map fields from request to view arguments
FastAPI tip:
You can use aliases for field names to map fields from request to view arguments.
https://fastapi.tiangolo.com/tutorial/query-params-str-validations/#alias-parameters
👇
from typing import Optional from fastapi import FastAPI, Query, Path app = FastAPI() @app.get("/products/") def search_products(query: Optional[str] = Query(None, alias="q")): products = [{"name": "Computer"}, {"name": "HDD"}] return {"results": [product for product in products if query in product["name"]]} @app.get("/users/{id}/profile/") def user_profile(user_id: int = Path(None, alias="id")): return { "id": user_id, "username": "johndoe" }
FastAPI Middleware
FastAPI tip:
You can add custom middleware to your app to do something before or after each request.
For example, to add a header containing the version of your application for easier debugging:
from fastapi import FastAPI, Request app = FastAPI() @app.middleware("http") async def add_version_header(request: Request, call_next): response = await call_next(request) response.headers["X-Version"] = "v1.2.10" return response @app.get("/ping") def ping(): return {"message": "pong"}
FastAPI - Using "callable" instances as dependencies in your API endpoints
FastAPI tip:
You can inject instances of a class as a dependency to your API endpoints, which you can then use when you as a configurable dependency.
You need to make instances callable via
__call__.https://fastapi.tiangolo.com/advanced/advanced-dependencies/#a-callable-instance
👇
from fastapi import FastAPI, Depends, HTTPException, status from pydantic import BaseModel class User(BaseModel): username: str groups: set[str] users = [ User(username='johndoe', groups={"admin"}), User(username='bobbuilder', groups={"builders"}), ] app = FastAPI() class AuthorizeUser: def __init__(self, allowed_groups: set[str]): self._allowed_groups = allowed_groups def __call__(self, username: str): try: user = next(user for user in users if user.username == username) except StopIteration: raise HTTPException(status_code=status.HTTP_401_UNAUTHORIZED) if user.groups.isdisjoint(self._allowed_groups): raise HTTPException(status_code=status.HTTP_401_UNAUTHORIZED) return user @app.get("/only-admins") def only_admins(user: User = Depends(AuthorizeUser(allowed_groups={"admin"}))): return {"message": f"User: {user.username} is in admin group."} @app.get("/only-builders") def only_admins(user: User = Depends(AuthorizeUser(allowed_groups={"builders"}))): return {"message": f"User: {user.username} is in builders group."}
FastAPI - API key authentication
FastAPI Tip:
You can protect API endpoints with an API key like so:
from fastapi import FastAPI, Body, Depends, HTTPException, status from fastapi.security import OAuth2PasswordBearer api_keys = [ "akljnv13bvi2vfo0b0bw" ] # This is encrypted in the database oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token") # use token authentication def api_key_auth(api_key: str = Depends(oauth2_scheme)): if api_key not in api_keys: raise HTTPException( status_code=status.HTTP_401_UNAUTHORIZED, detail="Forbidden" ) app = FastAPI() @app.get("/protected", dependencies=[Depends(api_key_auth)]) def add_post() -> dict: return { "data": "You used a valid API key." } #################################### # call API import requests url = "http://localhost:8000/protected" # The client should pass the API key in the headers headers = { 'Content-Type': 'application/json', 'Authorization': 'Bearer akljnv13bvi2vfo0b0bw' } response = requests.get(url, headers=headers) print(response.text) # => "You used a valid API key."
FastAPI - set cookie when returning a response
FastAPI tip:
You can set a cookie on the response by using
.set_cookie().Responsemust be added as a view argument.https://fastapi.tiangolo.com/advanced/response-cookies/
👇
from fastapi import FastAPI, Response app = FastAPI() @app.post("/session/") def cookie(response: Response): response.set_cookie(key="mysession", value="1242r") return {"message": "Wanna cookie?"}
FastAPI - Overriding dependencies while running tests
FastAPI tip:
You can override a dependency of your app while running tests with
dependency_overrides.For example, to connect to a test database:
from fastapi import Depends, FastAPI from fastapi.testclient import TestClient from pydantic import BaseModel from sqlalchemy.orm import Session, sessionmaker, declarative_base from sqlalchemy import create_engine, Column, Integer, String SQLALCHEMY_DATABASE_URL = "sqlite:///./sql_app.db" engine = create_engine( SQLALCHEMY_DATABASE_URL, connect_args={"check_same_thread": False} ) SessionLocal = sessionmaker(autocommit=False, autoflush=False, bind=engine) Base = declarative_base() class User(Base): __tablename__ = "users" id = Column(Integer, primary_key=True, index=True) email = Column(String, unique=True, index=True) Base.metadata.create_all(bind=engine) class UserSchema(BaseModel): email: str class Config: orm_mode = True app = FastAPI() # Dependency def get_db(): db = SessionLocal() try: yield db finally: db.close() @app.post("/users/", response_model=UserSchema) def create_user(user_data: UserSchema, database_session: Session = Depends(get_db)): db_user = User(email=user_data.email) database_session.add(db_user) database_session.commit() return db_user SQLALCHEMY_DATABASE_URL = "sqlite:///./test.db" engine = create_engine( SQLALCHEMY_DATABASE_URL, connect_args={"check_same_thread": False} ) TestingSessionLocal = sessionmaker(autocommit=False, autoflush=False, bind=engine) Base.metadata.create_all(bind=engine) def override_get_db(): db = TestingSessionLocal() try: yield db finally: db.close() # THIS app.dependency_overrides[get_db] = override_get_db # THIS client = TestClient(app) def test_create_user(): response = client.post( "/users/", json={"email": "[email protected]"}, ) assert response.status_code == 200
Python - set isdisjoint()
Python tip:
You can use
.isdisjoint()to check whether the intersection of two sets is empty -- i.e., there are not elements that are in the first and second sets.👇
winners = {"Carl", "Dan"} players = {"Daisy", "John", "Bob"} print(players.isdisjoint(winners)) # => True
Python - set symmetric_difference()
Python tip:
You can use
.symmetric_difference()to get a new set containing elements that are either in the first or second set but not in both.For example:
winners = {"John", "Marry"} players = {"Daisy", "John", "Bob"} print(players.symmetric_difference(winners)) # => {'Bob', 'Daisy', 'Marry'}
Python - set issubset()
Python tip:
You can use
.issubset()to check whether the second set contains the first one.👇
winners = {"John", "Marry"} players = {"Daisy", "John", "Bob", "Marry"} print(winners.issubset(players)) # => True
How to get the difference between two sets in Python
Python tip:
You can use
.difference()to get a new set that contains unique elements that are in the first set but not in the second one.For example:
winners = {"John", "Marry"} players = {"Daisy", "John", "Bob", "Marry"} print(players.difference(winners)) # => {'Bob', 'Daisy'}
Python Set Intersection
Python tip:
You can use
.intersection()to get a new set containing unique elements that are present inside two sets.👇
winners = {"John", "Marry"} players = {"Daisy", "John", "Bob", "Marry"} print(winners.intersection(players)) # => {'John', 'Marry'}
Union multiple sets in Python
Python tip:
You can use
.union()to create a new set containing unique elements that are either in the first set, the second set, or in both of them.👇
winners = {"John", "Marry"} players = {"Daisy", "John", "Bob", "Marry"} print(winners.union(players)) # => {'John', 'Marry', 'Bob', 'Daisy'}
Using a Python dictionary as a switch statement
Python tip:
You can use a dictionary to implement switch-like behavior.
For example:
class ProductionConfig: ELASTICSEARCH_URL = "https://elasticsearch.example.com" class DevelopmentConfig: ELASTICSEARCH_URL = "https://development-elasticsearch.example.com" class TestConfig: ELASTICSEARCH_URL = "http://test-in-docker:9200" CONFIGS = { "production": ProductionConfig, "development": DevelopmentConfig, "test": TestConfig, } def load_config(environment): return CONFIGS.get(environment, ProductionConfig) print(load_config("production")) # <class '__main__.ProductionConfig'> print(load_config("test")) # <class '__main__.TestConfig'> print(load_config("unknown")) # <class '__main__.ProductionConfig'>
Passing a dictionary as keyword arguments to a function in Python
Python tip:
You can use
**to unpack a dictionary as keyword arguments (kwargs) for a function.👇
user = {"name": "Jan", "surname": "Giacomelli"} def print_full_name(name, surname): print(f"{name} {surname}") print_full_name(**user) # => Jan Giacomelli
Remove duplicates from a Python list while preserving order
Python tip:
You can use a dictionary to remove duplicates from a list while preserving the order of elements:
users = ["Jan", "Mike", "Marry", "Mike"] print(list({user: user for user in users})) # => ['Jan', 'Mike', 'Marry']A dictionary preserves the insertion order.
How do I join dictionaries together in Python?
Python tip:
You can join two dictionaries using
**or|(for Python >= 3.9, works for all subclasses).If there are any duplicate keys, the second (rightmost) key-value pair is used.
user = {"name": "Jan", "surname": "Giacomelli"} address = {"address1": "Best street 42", "city": "Best city"} user_with_city = {**user, **address} print(user_with_city) # {'name': 'Jan', 'surname': 'Giacomelli', 'address1': 'Best street 42', 'city': 'Best city'} user_with_city = user | address print(user_with_city) # {'name': 'Jan', 'surname': 'Giacomelli', 'address1': 'Best street 42', 'city': 'Best city'} user_with_city = {"address": "Best street"} | {"address": "Almost best street"} print(user_with_city) # {'address': 'Almost best street'}
Prevent KeyError when working with dictionaries in Python
Python tip:
You can use
.get()to avoid a KeyError when accessing non-existing keys inside a dictionary:user = {"name": "Jan", "surname": "Giacomelli"} print(user.get("address", "Best street 42")) # => Best street 42 print(user["address"]) # => KeyError: 'address'If you don't provide a default value,
.get()will returnNoneif the key doesn't exist.If you're just trying to see if the key exists, it's better to use the
inoperator like so due to performance reasons:# good if "address" in user: print("yay") else: print("nay") # bad if user.get("address"): print("yay") else: print("nay")
Unpacking a list in Python
Python tip:
You can unpack list elements to variables. You can also ignore some of the elements.
👇
tournament_results = ["Jan", "Mike", "Marry", "Bob"] first_player, *_, last_player = tournament_results print(first_player, last_player) # => Jan Bob *_, last_player = tournament_results print(last_player) # => Bob first_player, *_ = tournament_results print(first_player) # => Jan first_player, second_player, third_player, fourth_player = tournament_results print(first_player, second_player, third_player, fourth_player) # => Jan Mike Marry Bob
Python - Iterate over multiple lists simultaneously with zip
Python tip:
You can use
zipto iterate through multiple lists of equal length in a single loop.👇
users = ["Jan", "Mike", "Marry", "Mike"] user_visits = [10, 31, 10, 1] for user, visits in zip(users, user_visits): print(f"{user}: {visits}") # Jan: 10 # Mike: 31 # Marry: 10 # Mike: 1
Count the number of occurrences of an element in a list in Python
Python tip:
You can count occurrences of an element in a list with
.count().For example:
users = ["Jan", "Mike", "Marry", "Mike"] print(users.count("Mike")) # => 2
How do I concatenate two lists in Python?
Python tip:
You can use
+to join two lists into a new list.a = [10, 2] b = [6, 3] print(a + b) # => [10, 2, 6, 3]
Python - create a list from a list repeated N times
Python tip:
You can create a new list with elements from the first list that are repeated as many times as you want by multiplying.
Fo example:
users = ["johndoe", "marry", "bob"] print(3 * users) # => ['johndoe', 'marry', 'bob', 'johndoe', 'marry', 'bob', 'johndoe', 'marry', 'bob']
Execute raw SQL queries in SQLAlchemy
Python SQLAlchemy tip:
You can use raw queries while still using SQLAlchemy models.
For example
user = session.query(Course).from_statement( text("""SELECT * FROM courses where title=:title""") ).params(title="Scalable FastAPI Applications on AWS").all()
Python - sep parameter in print()
Python tip:
You can pass as many values to print to the
print()function as you want. You can also specify a custom separator.print("123", "456", "789") # => 123 456 789 print("123", "456", "789", sep="-") # => 123-456-789
How to flush output of print in Python?
Python tip:
You can set
flush=Truefor theprint()function to avoid buffering the output data and forcibly flush it:print("I'm awesome", flush=True)
Python - find the last occurrence of an item in a list with rindex()
Python tip:
You can use
.rindex()to find the highest index in a string where a substring is found.👇
print("2021 was awesome. 2022 is going to be even more awesome.".rindex("awesome")) # => 48
Python - string ljust() method
Python tip:
You can use
.ljust()to create a left-justified string of given width.string.ljust(width, fillchar)Padding is a space, " ", by default.
print("Mike".ljust(10, "*")) # => Mike******
Python - string center() method
Python tip:
You can use
.center()to create a centered string of given width.string.center(width, fillchar)Padding on each side is a space, " ", by default.
print("Mike".center(10, "*")) # => ***Mike***
Python - lower() vs. casefold() for string matching and converting to lowercase
Python tip:
Use
.casfolde()instead of.lower()when you want to perform caseless operations when working with Unicode strings (for ASCII only strings they work the same) -- e.g., check if two strings are equal.# In German ß == ss print("straße".lower() == "strasse") # False print("straße".casefold() == "strasse") # True
Python - remove a prefix from a string
Python tip (>=3.9):
You can use
.removeprefix()to remove the prefix from a string.For example, to remove a filename prefix:
invoice_filenames = ("INV_123.pdf", "INV_234.pdf", "INV_345.pdf") for invoice_filename in invoice_filenames: print(invoice_filename.removeprefix("INV_")) # 123.pdf # 234.pdf # 345.pdf
Python - remove a suffix from a string
Python tip (>=3.9):
You can remove the suffix of a string with
.removesuffix().For example, to remove the file type from a filename:
import pathlib filename = "cv.pdf" file_type_suffix = pathlib.Path(filename).suffix print(filename.removesuffix(file_type_suffix)) # => cv
Pytest - Only run tests that match a substring expression
Pytest tip:
You can filter and run only tests that contain or do not contain some substring in their name.
Examples:
# run all tests that contain login in their name $ pytest -k login # run all tests that do not contain login in their name $ pytest -k 'not login'
CSRF Protection in Flask with Flask-WTF
Flask tip:
You can use Flask-WTF to implement CSRF protection for your application.
Example:
from flask import Flask, Response, abort, redirect, render_template, request, url_for from flask_login import ( LoginManager, UserMixin, current_user, login_required, login_user, logout_user, ) from flask_wtf.csrf import CSRFProtect app = Flask(__name__) app.config.update( DEBUG=True, SECRET_KEY="secret_sauce", ) login_manager = LoginManager() login_manager.init_app(app) csrf = CSRFProtect() csrf.init_app(app) ...You can read more here: https://testdriven.io/blog/csrf-flask/.
Contract Testing in Python
Python clean code tip:
Use contract testing when you want to verify the same behavior for different implementations.
Example:
import json import pathlib from dataclasses import dataclass import pytest @dataclass class User: username: str class InMemoryUserRepository: def __init__(self): self._users = [] def add(self, user): self._users.append(user) def get_by_username(self, username): return next(user for user in self._users if user.username == username) class JSONUserRepository: def __init__(self, file_path): self._users = json.load(pathlib.Path(file_path).open()) def add(self, user): self._users.append(user) def get_by_username(self, username): return next(user for user in self._users if user.username == username) class UserRepositoryContract: @pytest.fixture def repository(self): raise NotImplementedError('Not Implemented Yet') @pytest.fixture def username(self): return 'johndoe' @pytest.fixture def user(self, username): return User(username=username) def test_added_user_is_retrieved_by_username(self, username, user, repository): repository.add(user) assert repository.get_by_username(user.username).username == username class TestInMemoryUserRepository(UserRepositoryContract): @pytest.fixture def repository(self): return InMemoryUserRepository() class TestInJSONUserRepository(UserRepositoryContract): @pytest.fixture def repository(self, tmp_path): users_file = tmp_path/"user.json" users_file.write_text(json.dumps([])) return JSONUserRepository(users_file)
Simplify Testing with Dependency Injection
Python clean code tip:
Use dependency injection to simplify testing
Example:
from dataclasses import dataclass from fastapi import FastAPI @dataclass class User: username: str class StartUserOnboarding: def __init__(self, user_repository): self._user_repository = user_repository def execute(self, username): user = User(username=username) self._user_repository.add(user) class InMemoryUserRepository: def __init__(self): self._users = [] def add(self, user): self._users.append(user) def get_by_username(self, username): return next(user for user in self._users if user.username == username) class SQLiteUserRepository: def __init__(self, config): self._config = config def add(self, user): print(f"Running some SQL statements for insert DATABASE_PATH") def get_by_username(self, username): print(f"Running some SQL statements for fetch from {self._config.DATABASE_PATH}") def test_user_is_added_to_repository(): username = "[email protected]" repository = InMemoryUserRepository() use_case = StartUserOnboarding(user_repository=repository) use_case.execute(username) assert repository.get_by_username(username).username class ApplicationConfig: DATABASE_PATH = "db" app = FastAPI() @app.post("/users/start-onboarding", status_code=202) async def start_user_onboarding(username: str): StartUserOnboarding(SQLiteUserRepository(ApplicationConfig())).execute(username) return "OK"
Python - use enums to group related constants
Python clean code tip:
Use enums to group related constants.
Why?
- Autocomplete
- Static type checking
Example:
from dataclasses import dataclass from enum import Enum # bad ORDER_PLACED = "PLACED" ORDER_CANCELED = "CANCELED" ORDER_FULFILLED = "FULFILLED" @dataclass class Order: status: str order = Order(ORDER_PLACED) print(order) # better class OrderStatus(str, Enum): PLACED = "PLACED" CANCELED = "CANCELED" FULFILLED = "FULFILLED" @dataclass class Order: status: OrderStatus order = Order(OrderStatus.PLACED) print(order)
Interfaces in Python with Protocol Classes
Python clean code tip:
Use
Protocolto define the interface required by your function/method instead of using real objects. This way your function/method defines what it needs.from typing import Protocol class ApplicationConfig: DEBUG = False SECRET_KEY = "secret-key" EMAIL_API_KEY = "api-key" # bad def send_email(config: ApplicationConfig): print(f"Send email using API key: {config.EMAIL_API_KEY}") # better class EmailConfig(Protocol): EMAIL_API_KEY: str def send_email_(config: EmailConfig): print(f"Send email using API key: {config.EMAIL_API_KEY}")
Python - Property-based Testing with Hypothesis
Python testing tip:
Rather than having to write different test cases for every argument you want to test, property-based testing generates a wide-range of random test data that's dependent on previous tests runs.
Use Hypothesis for this:
def increment(num: int) -> int: return num + 1 # regular test import pytest @pytest.mark.parametrize( 'number, result', [ (-2, -1), (0, 1), (3, 4), (101234, 101235), ] ) def test_increment(number, result): assert increment(number) == result # property-based test from hypothesis import given import hypothesis.strategies as st @given(st.integers()) def test_add_one(num): assert increment(num) == num - 1
Python - mock.create_autospec()
Python tip:
Use
mock.create_autospec()to create a mock object with methods that have the same interface as the ones inside the original object.Example:
from unittest import mock import requests from requests import Response def get_my_ip(): response = requests.get( 'http://ipinfo.io/json' ) return response.json()['ip'] def test_get_my_ip(monkeypatch): my_ip = '123.123.123.123' response = mock.create_autospec(Response) response.json.return_value = {'ip': my_ip} monkeypatch.setattr( requests, 'get', lambda *args, **kwargs: response ) assert get_my_ip() == my_ip
Pytest - clean up resources at the end of a test session
Python clean test tip:
Clean up resources needed for test after the pytest session is finished -- i.e., drop test database, remove files added to the file system.
Example:
import csv import os import pathlib import pytest def list_users_from_csv(file_path): return [ {field_name: field_value for field_name, field_value in row.items()} for row in csv.DictReader( file_path.open(), skipinitialspace=True, fieldnames=["first_name", "last_name"], ) ] @pytest.fixture def users_csv_path(): # before test - create resource file_path = pathlib.Path("users.csv") file_path.write_text("Jan,Giacomelli") yield file_path # after test - remove resource file_path.unlink() def test_all_users_are_listed(users_csv_path): assert list_users_from_csv(users_csv_path) == [ {"first_name": "Jan", "last_name": "Giacomelli"} ]
Arrange-Act-Assert - testing pattern
Python clean test tip:
Structure your tests in an Arrange-Act-Assert way:
- Arrange - set-up logic
- Act - invokes the system you're about to test
- Assert - verifies that the action of the system under test behaves as expected
Example:
from dataclasses import dataclass @dataclass class User: first_name: str last_name: str def full_name(self): return f"{self.first_name} {self.last_name}" def test_full_name_consists_of_first_name_and_last_name(): # arrange first_name = "John" last_name = "Doe" user = User(first_name=first_name, last_name=last_name) # act full_name = user.full_name() # assert assert full_name == "John Doe"
Pytest - Parameterizing Tests
Python clean test tip:
Use pytest
parametrizewhen you need multiple cases to prove a single behavior.Example:
import difflib import pytest def names_are_almost_equal(first, second): return difflib.SequenceMatcher(None, first, second).ratio() > 0.7 @pytest.mark.parametrize( "first,second", [ ("John", "Johny"), ("Many", "Mary"), ] ) def test_names_are_almost_equal(first, second): assert names_are_almost_equal(first, second) @pytest.mark.parametrize( "first,second", [ ("John", "Joe"), ("Daisy", "Serena"), ] ) def test_names_are_not_almost_equal(first, second): assert not names_are_almost_equal(first, second)
Hide irrelevant test data
Python clean test tip:
You should hide irrelevant data for the test.
Such information just increases the cognitive mental load, resulting in bloated tests.
Example:
import uuid from dataclasses import dataclass from enum import Enum from uuid import UUID import pytest class ProductCategory(str, Enum): BOOK = "BOOK" ELECTRONIC = "ELECTRONIC" @dataclass class Product: id: UUID price: int name: str category: ProductCategory class ShoppingCart: def __init__(self): self._products = [] def add(self, product): self._products.append(product) def calculate_total_price(self): return sum(product.price for product in self._products) # BAD - category, id, and name are irrelevant for this test def test_given_products_with_total_price_50_when_calculate_total_price_then_total_price_is_50_(): shopping_cart = ShoppingCart() shopping_cart.add(Product(uuid.uuid4(), 10, "Mobile phone case", ProductCategory.ELECTRONIC)) shopping_cart.add(Product(uuid.uuid4(), 20, "Never enough", ProductCategory.BOOK)) shopping_cart.add(Product(uuid.uuid4(), 20, "Mobile phone charger", ProductCategory.ELECTRONIC)) assert shopping_cart.calculate_total_price() == 50 # GOOD @pytest.fixture def product_with_price(): def _product_with_price(price): return Product(uuid.uuid4(), price, "Mobile phone case", ProductCategory.ELECTRONIC) return _product_with_price def test_given_products_with_total_price_50_when_calculate_total_price_then_total_price_is_50(product_with_price): shopping_cart = ShoppingCart() shopping_cart.add(product_with_price(10)) shopping_cart.add(product_with_price(20)) shopping_cart.add(product_with_price(20)) assert shopping_cart.calculate_total_price() == 50
Tests should use meaningful data
Python clean test tip:
Your tests should use meaningful data in order to provide examples of how to use your code.
Examples:
from dataclasses import dataclass @dataclass class Car: manufacture: str model: str vin_number: str top_speed: int class InMemoryCarRepository: def __init__(self): self._cars = [] def add(self, car): self._cars.append(car) def get_by_vin_number(self, vin_number): return next(car for car in self._cars if car.vin_number == vin_number) # BAD - non-existing manufacture and model, VIN number not matching manufacture and model, impossible to reach top speed def test_added_car_can_be_retrieved_by_vin_number_(): car = Car(manufacture="AAAA", model="BBB+", vin_number="2FTJW36M6LCA90573", top_speed=1600) repository = InMemoryCarRepository() repository.add(car) assert car == repository.get_by_vin_number(car.vin_number) # GOOD def test_added_car_can_be_retrieved_by_vin_number(): car = Car(manufacture="Jeep", model="Wrangler", vin_number="1J4FA29P4YP728937", top_speed=160) repository = InMemoryCarRepository() repository.add(car) assert car == repository.get_by_vin_number(car.vin_number)
What should tests cover?
Python clean test tip:
For the most part, the tests you write should cover:
- all happy paths
- edge/corner/boundary cases
- negative test cases
- security and illegal issues
👇
import uuid from dataclasses import dataclass from typing import Optional @dataclass class User: username: str class InMemoryUserRepository: def __init__(self): self._users = [] def add(self, user: User) -> None: self._users.append(user) def search(self, query: Optional[str] = None) -> list[User]: if query is None: return self._users else: return [ user for user in self._users if query in user.username ] # happy path def test_search_users_without_query_lists_all_users(): user1 = User(username="[email protected]") user2 = User(username="[email protected]") repository = InMemoryUserRepository() repository.add(user1) repository.add(user2) assert repository.search() == [user1, user2] # happy path def test_search_users_with_email_part_lists_all_matching_users(): user1 = User(username="[email protected]") user2 = User(username="[email protected]") user3 = User(username="[email protected]") repository = InMemoryUserRepository() repository.add(user1) repository.add(user2) repository.add(user3) assert repository.search("doe") == [user1, user3] # edge test case def test_search_users_with_empty_query_lists_all_users(): user1 = User(username="[email protected]") user2 = User(username="[email protected]") repository = InMemoryUserRepository() repository.add(user1) repository.add(user2) assert repository.search("") == [user1, user2] # negative test case def test_search_users_with_random_query_lists_zero_users(): user1 = User(username="[email protected]") repository = InMemoryUserRepository() repository.add(user1) assert repository.search(str(uuid.uuid4())) == [] # security test def test_search_users_with_sql_injection_has_no_effect(): user1 = User(username="[email protected]") repository = InMemoryUserRepository() repository.add(user1) repository.search("DELETE FROM USERS;") assert repository.search() == [user1]
Tests should validate themselves regardless of whether the test execution passes or fails
Python clean test tip:
A test should validate itself whether the test execution is passed or failed.
The self-validating test can avoid the need to do an evaluation manually by us.
Example:
from dataclasses import dataclass @dataclass class User: first_name: str last_name: str def fullname(self): return f"{self.first_name} {self.last_name}" # BAD def test_full_name_consists_of_first_name_and_last_name_manual(): first_name = "John" last_name = "Doe" user = User(first_name=first_name, last_name=last_name) print(user.fullname()) assert input("Is result correct? (Y/n)") == "Y" # GOOD def test_full_name_consists_of_first_name_and_last_name(): first_name = "John" last_name = "Doe" full_name = "John Doe" user = User(first_name=first_name, last_name=last_name) assert user.fullname() == full_name
Tests should be independent
Python clean test tip:
A test should not depend on the state of any other tests or external services.
👇
from dataclasses import dataclass import pytest @dataclass class User: username: str class InMemoryUserRepository: def __init__(self): self._users = [] def add(self, user: User) -> None: self._users.append(user) def get_by_username(self, username: str) -> User: return next( user for user in self._users if user.username == username ) # BAD - depends on persistence layer having user record at test time def test_get_by_username(): user = User(username="[email protected]") repository = InMemoryUserRepository() assert repository.get_by_username(user.username) == user # BAD - test_user_is_fetched_by_username will succeed only when running after test_added_user @pytest.fixture(scope="module") def repository(): return InMemoryUserRepository() def test_added_user(repository): user = User(username="[email protected]") assert repository.add(user) is None def test_user_is_fetched_by_username(repository): user = User(username="[email protected]") assert repository.get_by_username(user.username) == user # GOOD - makes sure it has all the needed data def test_added_user_is_fetched_by_username(): user = User(username="[email protected]") repository = InMemoryUserRepository() repository.add(user) assert repository.get_by_username(user.username) == user
Tests should be repeatable and deterministic
Python clean test tip:
Your tests should be repeatable in any environment.
They should be deterministic, always result in the same tests succeeding.
Example:
import random LOTTO_COMBINATION_LENGTH = 5 MIN_LOTTO_NUMBER = 1 MAX_LOTTO_NUMBER = 42 def lotto_combination(): combination = [] while len(combination) < LOTTO_COMBINATION_LENGTH: number = random.randint(MIN_LOTTO_NUMBER, MAX_LOTTO_NUMBER) if number not in combination: combination.append(number) return combination # BAD def test_lotto_combination(): assert lotto_combination() == [10, 33, 5, 7, 2] # GOOD def test_all_numbers_are_between_min_max_range(): assert all(MIN_LOTTO_NUMBER <= number <= MAX_LOTTO_NUMBER for number in lotto_combination()) def test_length_of_lotto_combination_has_expected_number_of_elements(): assert len(lotto_combination()) == LOTTO_COMBINATION_LENGTH
Shorten your feedback loops by increasing the speed of your test suite
Python clean test tip:
Your tests should be fast. The faster the tests the faster the feedback loop.
Consider using mocks or test doubles when dealing with third-party APIs and other slow things.
Example:
import time def fetch_articles(): print("I'm fetching articles from slow API") time.sleep(10) return {"articles": [{"title": "Facebook is Meta now."}]} # BAD def test_fetch_articles_slow(): assert fetch_articles() == {"articles": [{"title": "Facebook is Meta now."}]} # GOOD def test_fetch_articles_fast(monkeypatch): monkeypatch.setattr(time, "sleep", lambda timeout: None) assert fetch_articles() == {"articles": [{"title": "Facebook is Meta now."}]}
Tests should be useful
Python clean test tip:
Tests should protect you against regressions. They shouldn't just increase your code coverage percentage. Make sure they are useful! Don't just write tests for the sake of writing tests. They are code too, so they need to be maintained.
Example:
from dataclasses import dataclass @dataclass class User: first_name: str last_name: str def fullname(self): return f"{self.first_name} {self.last_name}" # BAD def test_full_name(): user = User(first_name="John", last_name="Doe") assert user.fullname() is not None # GOOD def test_full_name_consists_of_first_name_and_last_name(): first_name = "John" last_name = "Doe" full_name = "John Doe" user = User(first_name=first_name, last_name=last_name) assert user.fullname() == full_name
Test behavior, not implementation
Python clean test tip:
Tests should check the behavior rather than the underlying implementation details.
Such tests are easier to understand and maintain. They're also more resistant to refactoring (helps prevent false negatives).
👇
from dataclasses import dataclass @dataclass class User: username: str class InMemoryUserRepository: def __init__(self): self._users = [] def add(self, user): self._users.append(user) def get_by_username(self, username): return next(user for user in self._users if user.username == username) # BAD def test_add(): user = User(username="johndoe") repository = InMemoryUserRepository() repository.add(user) assert user in repository._users def test_get_by_username(): user = User(username="johndoe") repository = InMemoryUserRepository() repository._users = [user] user_from_repository = repository.get_by_username(user.username) assert user_from_repository == user # GOOD def test_added_user_can_be_retrieved_by_username(): user = User(username="johndoe") repository = InMemoryUserRepository() repository.add(user) assert user == repository.get_by_username(user.username)
Tests should fail for exactly one reason - aim for a single assert per test
Python clean test tip:
Aim for a single assert per test. Tests will be more readable and it's easier to locate a defect when a test is failing.
Example:
import pytest class User: def __init__(self, username): if len(username) < 1: raise Exception("Username must not be empty.") self._username = username @property def username(self): return self._username # BAD def test_user(): username = "johndoe" assert User(username).username == username username = "" with pytest.raises(Exception): User(username) # GOOD def test_user_with_valid_username_can_be_initialized(): username = "johndoe" assert User(username).username == username def test_user_with_empty_username_cannot_be_initialized(): username = "" with pytest.raises(Exception): User(username)It's fine to deviate from this, to include multiple asserts per test as long as you're testing the same concept.
Testing Naming Conventions - GIVEN-WHEN-THEN
Python clean test tip:
Tests should have descriptive names to reveal their intention. For example, you could follow GIVEN-WHEN-THEN or SHOULD-WHEN naming conventions:
import pytest from fastapi import FastAPI from fastapi.testclient import TestClient from pydantic import BaseModel app = FastAPI() class LoginRequest(BaseModel): username: str password: str @app.post("/login") def login(data: LoginRequest): return {"access_token": "1234"} @pytest.fixture() def client(): yield TestClient(app) # BAD def test_login(client): response = client.post("/login", json={"username": "johndoe", "password": "correct_password"}) assert response.status_code == 200 assert response.json()["access_token"] == "1234" # GOOD def test_valid_username_and_password_combination_can_be_exchanged_for_access_token(client): response = client.post("/login", json={"username": "johndoe", "password": "correct_password"}) assert response.status_code == 200 assert response.json()["access_token"] == "1234" def test_given_valid_username_and_password_combination_when_user_calls_login_then_access_token_is_returned(client): response = client.post("/login", json={"username": "johndoe", "password": "correct_password"}) assert response.status_code == 200 assert response.json()["access_token"] == "1234" def test_access_token_should_be_returned_when_valid_username_and_password_combination_is_provided(client): response = client.post("/login", json={"username": "johndoe", "password": "correct_password"}) assert response.status_code == 200 assert response.json()["access_token"] == "1234"
Docker - Use COPY --chown instead of RUN chown after COPY in Dockerfile
Docker best practice:
Use
--chownoption of Docker's COPY command instead of doing it manually to reduce build time.# manually changing owner COPY . $APP_HOME RUN chown -r app:app $APP_HOME # using --chown option COPY --chown=app:app . $APP_HOME
Docker and Python Virtual Environments
Docker tip:
You can use a virtual environment instead of building wheels in multi-stage builds.
For example:
# temp stage FROM python:3.9-slim as builder WORKDIR /app ENV PYTHONDONTWRITEBYTECODE 1 ENV PYTHONUNBUFFERED 1 RUN apt-get update && \ apt-get install -y --no-install-recommends gcc RUN python -m venv /opt/venv ENV PATH="/opt/venv/bin:$PATH" COPY requirements.txt . RUN pip install -r requirements.txt # final stage FROM python:3.9-slim COPY --from=builder /opt/venv /opt/venv WORKDIR /app ENV PATH="/opt/venv/bin:$PATH"Note: This is one of the only use cases for using a Python virtual environment with Docker.
- Install the dependencies in the builder image within a virtual environment.
- Copy over the dependencies to the final image
This reduces the size of the final image significantly.
Docker Logging Best Practices - stdout and stderr
Docker best practice:
Your Docker applications should log to standard output (stdout) and standard error (stderr) rather than to a file.
You can then configure the Docker daemon to send your log messages to a centralized logging solution (like CloudWatch or Papertrail).
Set Docker Memory and CPU Limits
Docker best practice:
Limit CPU and memory for your containers to prevent crippling the rest of the containers on the machine.
Examples:
# using docker run $ docker run --cpus=2 -m 512m nginx # using docker-compose version: "3.9" services: redis: image: redis:alpine deploy: resources: limits: cpus: 2 memory: 512M reservations: cpus: 1 memory: 256M
Sign and Verify Docker Images
Docker best practice:
Sign and verify your Docker images to prevent running images that have been tampered with.
To verify the integrity and authenticity of an image, set the
DOCKER_CONTENT_TRUSTenvironment variable:DOCKER_CONTENT_TRUST=1
Lint and Scan Your Dockerfiles and Images
Docker best practice:
Lint and scan your Dockerfiles and images to check your code for programmatic and stylistic errors and bad practices that could lead to potential flaws.
Some options:
👇
hadolint Dockerfile Dockerfile:1 DL3006 warning: Always tag the version of an image explicitly Dockerfile:7 DL3042 warning: Avoid the use of cache directory with pip. Use `pip install --no-cache-dir <package>` Dockerfile:9 DL3059 info: Multiple consecutive `RUN` instructions. Consider consolidation. Dockerfile:17 DL3025 warning: Use arguments JSON notation for CMD and ENTRYPOINT arguments
Use a .dockerignore File
A properly structured .dockerignore file can help:
- Decrease the size of the Docker image
- Speed up the build process
- Prevent unnecessary cache invalidation
- Prevent leaking secrets
Example:
**/.git **/.gitignore **/.vscode **/coverage **/.env **/.aws **/.ssh Dockerfile README.md docker-compose.yml **/.DS_Store **/venv **/env
Don't Embed Secrets in Docker Images
Docker best practice:
Don't store secrets in Docker images.
Instead, they should be injected via:
- Environment variables (at run-time)
- Build-time arguments (at build-time)
- An orchestration tool like Docker Swarm (via Docker secrets) or Kubernetes (via Kubernetes secrets)
For more along with examples, check out Don't Store Secrets in Images.