 Samuel Torimiro
Samuel Torimiro
Unlike relational databases, full-text search is not standardized. There are several open-source options like ElasticSearch, Solr, and Xapian. ElasticSearch is probably the most popular solution; however, it's complicated to set up and maintain. Further, if you're not taking advantage of some of the advanced features that ElasticSearch offers, you should stick with the full-text search capabilities that many relational (like Postgres, MySQL, SQLite) and non-relational databases (like MongoDB and CouchDB) offer. Postgres in particular is well-suited for full-text search. Django supports it out-of-the-box as well.
For the vast majority of your Django apps, you should, at the very least, start out with leveraging full-text search from Postgres before looking to a more powerful solution like ElasticSearch or Solr.
In this tutorial, you'll learn how to add basic and full-text search to a Django app with Postgres. You'll also optimize the full-text search by adding a search vector field and a database index.
This is an intermediate-level tutorial. It assumes that you're familiar with both Django and Docker. Review the Dockerizing Django with Postgres, Gunicorn, and Nginx tutorial for more info.
Contents
Objectives
By the end of this tutorial, you will be able to:
- Set up basic search functionality in a Django app with the Q object module
- Add full-text search to a Django app
- Sort full-text search results by relevance using stemming, ranking, and weighting techniques
- Add a preview to your search results
- Optimize full-text search with a search vector field and a database index
Project Setup and Overview
Clone down the base branch from the django-search repo:
$ git clone https://github.com/testdrivenio/django-search --branch base --single-branch
$ cd django-search
You'll use Docker to simplify setting up and running Postgres along with Django.
From the project root, create the images and spin up the Docker containers:
$ docker-compose up -d --build
Next, apply the migrations and create a superuser:
$ docker-compose exec web python manage.py makemigrations
$ docker-compose exec web python manage.py migrate
$ docker-compose exec web python manage.py createsuperuser
Once done, navigate to http://127.0.0.1:8011/quotes/ to ensure the app works as expected. You should see the following:
Want to learn how to work with Django and Postgres? Check out the Dockerizing Django with Postgres, Gunicorn, and Nginx article.
Take note of the Quote model in quotes/models.py:
from django.db import models
class Quote(models.Model):
name = models.CharField(max_length=250)
quote = models.TextField(max_length=1000)
def __str__(self):
return self.quote
Next, run the following management command to add 10,000 quotes to the database:
$ docker-compose exec web python manage.py add_quotes
This will take a couple of minutes. Once done, navigate to http://127.0.0.1:8011/quotes/ to see the data.
The output of the view is cached for five minutes, so you may want to comment out the
@method_decoratorin quotes/views.py to load the quotes. Make sure to remove the comment once done.

In the quotes/templates/quote.html file, you have a basic form with a search input field:
<form action="{% url 'search_results' %}" method="get">
<input
type="search"
name="q"
placeholder="Search by name or quote..."
class="form-control"
/>
</form>
On submit, the form sends the data to the backend. A GET request is used rather than a POST so that way we have access to the query string both in the URL and in the Django view, allowing users to share search results as links.
Before proceeding further, take a quick look at the project structure and the rest of the code.
Basic Search
When it comes to search, with Django, you'll typically start by performing search queries with contains or icontains for exact matches. The Q object can be used as well to add AND (&) or OR (|) logical operators.
For instance, using the OR operator, override theSearchResultsList's default QuerySet in quotes/views.py like so:
class SearchResultsList(ListView):
model = Quote
context_object_name = "quotes"
template_name = "search.html"
def get_queryset(self):
query = self.request.GET.get("q")
return Quote.objects.filter(
Q(name__icontains=query) | Q(quote__icontains=query)
)
Here, we used the filter method to filter against the name or quote fields. Furthermore, we used the icontains extension to check if the query is present in the name or quote fields (case insensitive). A positive result will be returned if a match is found.
Don't forget the import:
from django.db.models import Q
Try it out:

For small data sets, this is a great way to add basic search functionality to your app. If you're dealing with a large data set or want search functionality that feels like an Internet search engine, you'll want to move to full-text search.
Full-text Search
The basic search that we saw earlier has several limitations especially when you want to perform complex lookups.
As mentioned, with basic search, you can only perform exact matches.
Another limitation is that of stop words. Stop words are words such as "a", "an", and "the". These words are common and insufficiently meaningful, therefore they should be ignored. To test, try searching for a word with "the" in front of it. Say you searched for "the middle". In this case, you'll only see results for "the middle", so you won't see any results that have the word "middle" without "the" before it.
Say you have these two sentences:
- I am in the middle.
- You don't like middle school.
You'll get the following returned with each type of search:
| Query | Basic Search | Full-text Search |
|---|---|---|
| "the middle" | 1 | 1 and 2 |
| "middle" | 1 and 2 | 1 and 2 |
Another issue is that of ignoring similar words. With basic search, only exact matches are returned. However, with full-text search, similar words are accounted for. To test, try to find some similar words like "pony" and "ponies". With basic search, if you search for "pony" you won't see results that contain "ponies" -- and vice versa.
Say you have these two sentences:
- I am a pony.
- You don't like ponies
You'll get the following returned with each type of search:
| Query | Basic Search | Full-text Search |
|---|---|---|
| "pony" | 1 | 1 and 2 |
| "ponies" | 2 | 1 and 2 |
With full-text search, both of these issues are mitigated. However, keep in mind that depending on your goal, full-text search may actually decrease precision (quality) and recall (quantity of relevant results). Typically, full-text search is less precise than basic search, since basic search yields exact matches. That said, if you're searching through large data sets with large blocks of text, full-text search is preferred since it's usually much faster.
Full-text search is an advanced searching technique that examines all the words in every stored document as it tries to match the search criteria. In addition, with full-text search, you can employ language-specific stemming on the words being indexed. For instance, the word "drives", "drove", and "driven" will be recorded under the single concept word "drive". Stemming is the process of reducing words to their word stem, base, or root form.
It suffices to say that full-text search is not perfect. It's likely to retrieve many documents that are not relevant (false positives) to the intended search query. However, there are some techniques based on Bayesian algorithms that can help reduce such problems.
To take advantage of Postgres full-text search with Django, add django.contrib.postgres to your INSTALLED_APPS list:
INSTALLED_APPS = [
...
"django.contrib.postgres", # new
]
Next, let's look at two quick examples of full-text search, on a single field and on multiple fields.
Single Field Search
Update the get_queryset function under the SearchResultsList view function like so:
class SearchResultsList(ListView):
model = Quote
context_object_name = "quotes"
template_name = "search.html"
def get_queryset(self):
query = self.request.GET.get("q")
return Quote.objects.filter(quote__search=query)
Here, we set up full-text search against a single field -- the quote field.
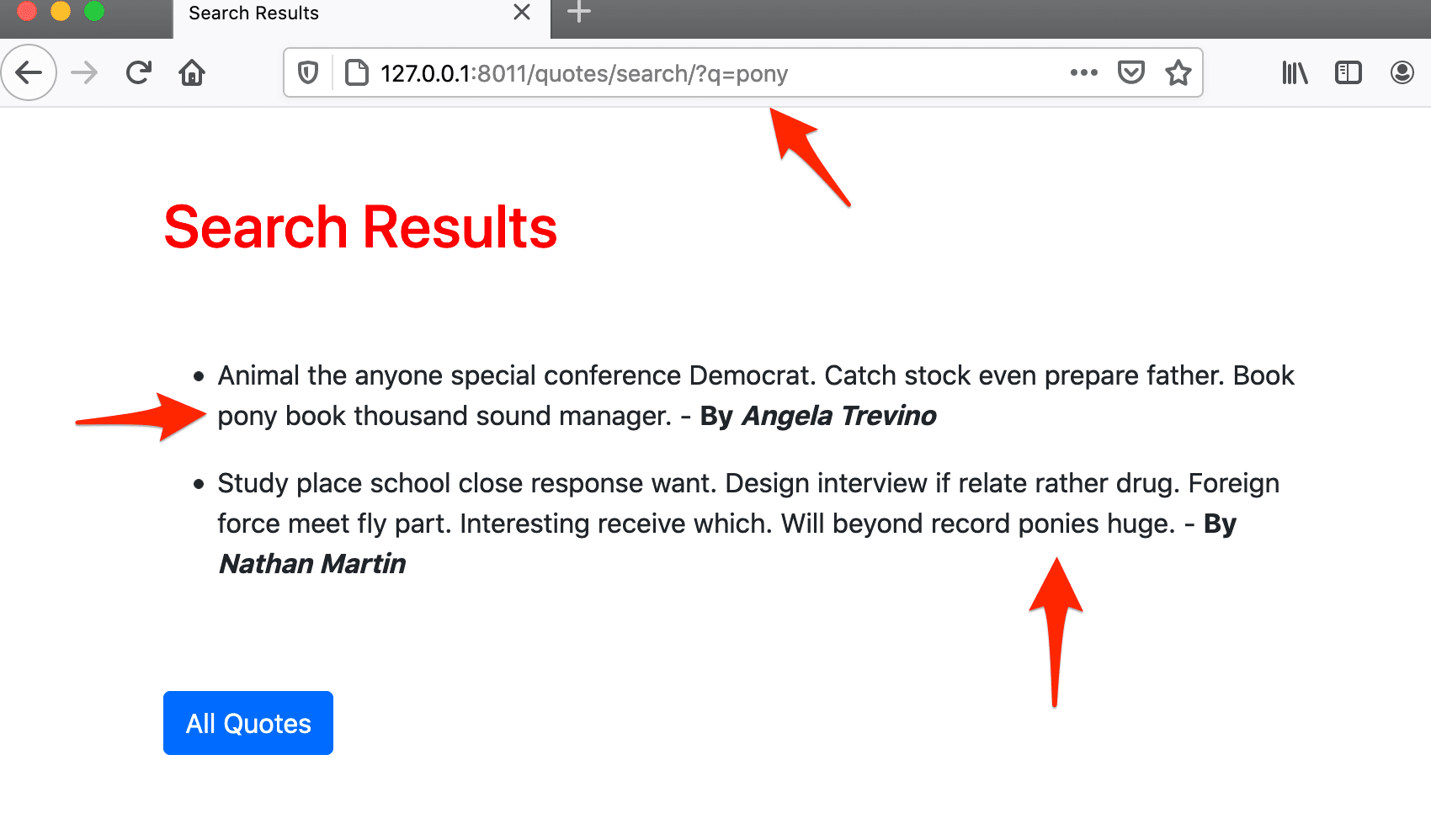
As you can see, it takes similar words into account. In the above example, "ponies" and "pony" are treated as similar words.
Multi Field Search
To search against multiple fields and on related models, you can use the SearchVector class.
Again, update SearchResultsList:
class SearchResultsList(ListView):
model = Quote
context_object_name = "quotes"
template_name = "search.html"
def get_queryset(self):
query = self.request.GET.get("q")
return Quote.objects.annotate(search=SearchVector("name", "quote")).filter(
search=query
)
To search against multiple fields, you annotated the queryset using a SearchVector. The vector is the data that you're searching for, which has been converted into a form that is easy to search. In the example above, this data is the name and quote fields in your database.
Make sure to add the import:
from django.contrib.postgres.search import SearchVector
Try some searches out.
Stemming and Ranking
In this section, you'll combine several methods such as SearchVector, SearchQuery, and SearchRank to produce a very robust search that uses both stemming and ranking.
Again, stemming is the process of reducing words to their word stem, base, or root form. With stemming, words like "child" and "children" will be treated as similar words. Ranking, on the other hand, allows us to order results by relevancy.
Update SearchResultsList:
class SearchResultsList(ListView):
model = Quote
context_object_name = "quotes"
template_name = "search.html"
def get_queryset(self):
query = self.request.GET.get("q")
search_vector = SearchVector("name", "quote")
search_query = SearchQuery(query)
return (
Quote.objects.annotate(
search=search_vector, rank=SearchRank(search_vector, search_query)
)
.filter(search=search_query)
.order_by("-rank")
)
What's happening here?
SearchVector- again you used a search vector to search against multiple fields. The data is converted into another form since you're no longer just searching the raw text like you did whenicontainswas used. Therefore, with this, you will be able to search plurals easily. For example, searching for "flask" and "flasks" will yield the same search because they are, well, basically the same thing.SearchQuery- translates the words provided to us as a query from the form, passes them through a stemming algorithm, and then it looks for matches for all of the resulting terms.SearchRank- allows us to order the results by relevancy. It takes into account how often the query terms appear in the document, how close the terms are on the document, and how important the part of the document is where they occur.
Add the imports:
from django.contrib.postgres.search import SearchVector, SearchQuery, SearchRank
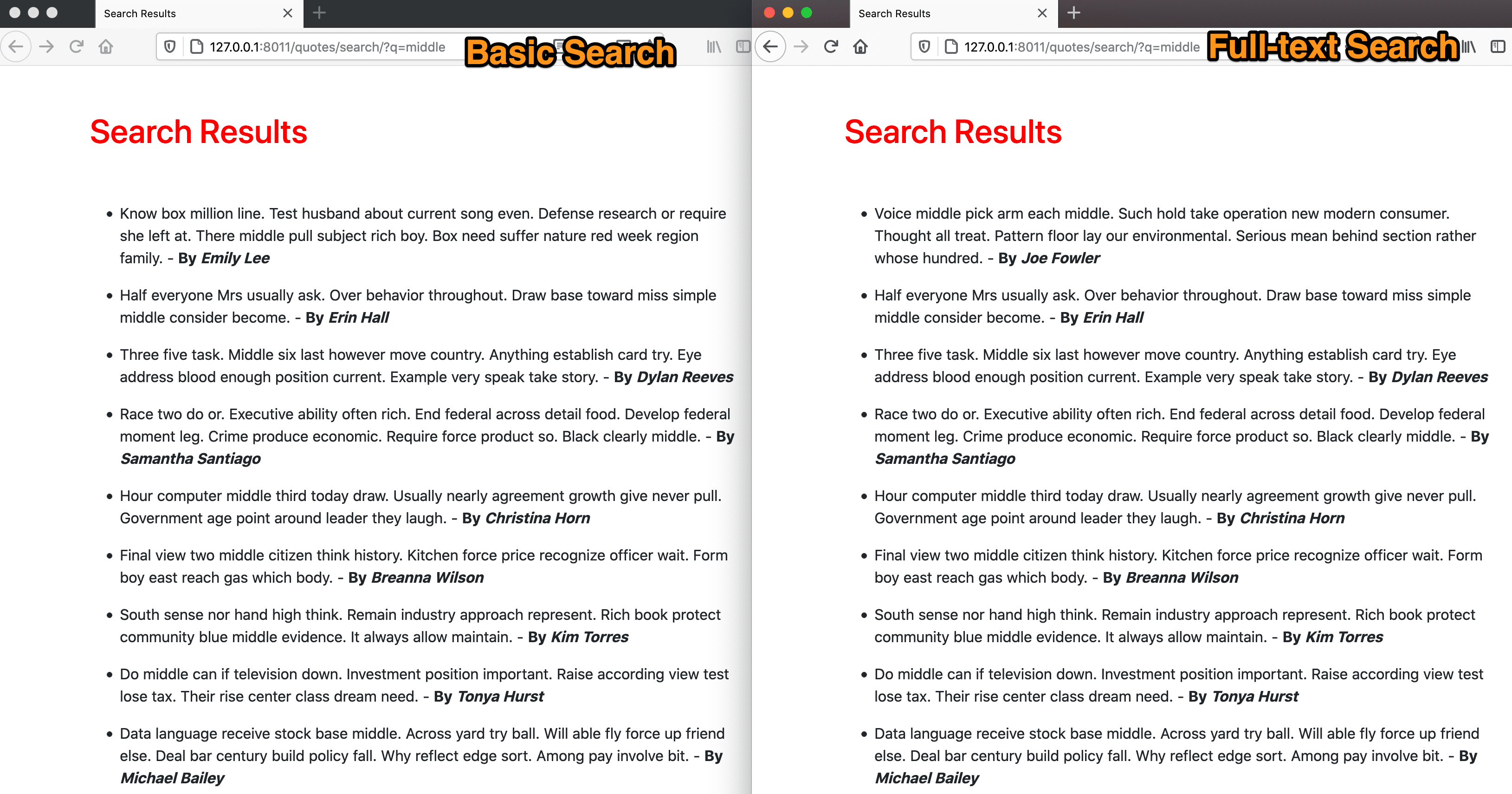
Compare the results from the basic search to that of the full-text search. There's a clear difference. In the full-text search, the query with the highest results is shown first. This is the power of SearchRank. Combining SearchVector, SearchQuery, and SearchRank is a quick way to produce a much more powerful and precise search than the basic search.
Adding Weights
Full-text search gives us the ability to add more importance to some fields in our table in the database over other fields. We can achieve this by adding weights to our queries.
The weight should be one of the following letters D, C, B, A. By default, these weights refer to the numbers 0.1, 0.2, 0.4, and 1.0, respectively.
Update SearchResultsList:
class SearchResultsList(ListView):
model = Quote
context_object_name = "quotes"
template_name = "search.html"
def get_queryset(self):
query = self.request.GET.get("q")
search_vector = SearchVector("name", weight="B") + SearchVector(
"quote", weight="A"
)
search_query = SearchQuery(query)
return (
Quote.objects.annotate(rank=SearchRank(search_vector, search_query))
.filter(rank__gte=0.3)
.order_by("-rank")
)
Here, you added weights to the SearchVector using both the name and quote fields. Weights of 0.4 and 1.0 were applied to the name and quote fields, respectively. Therefore, quote matches will prevail over name content matches. Finally, you filtered the results to display only the ones that are greater than 0.3.
Adding a Preview to the Search Results
In this section, you'll add a little preview of your search result via the SearchHeadline method. This will highlight the search result query.
Update SearchResultsList again:
class SearchResultsList(ListView):
model = Quote
context_object_name = "quotes"
template_name = "search.html"
def get_queryset(self):
query = self.request.GET.get("q")
search_vector = SearchVector("name", "quote")
search_query = SearchQuery(query)
search_headline = SearchHeadline("quote", search_query)
return Quote.objects.annotate(
search=search_vector,
rank=SearchRank(search_vector, search_query)
).annotate(headline=search_headline).filter(search=search_query).order_by("-rank")
The SearchHeadline takes in the field you want to preview. In this case, this will be the quote field along with the query, which will be in bold.
Make sure to add the import:
from django.contrib.postgres.search import SearchVector, SearchQuery, SearchRank, SearchHeadline
Before trying out some searches, update the <li></li> in quotes/templates/search.html like so:
<li>{{ quote.headline | safe }} - <b>By <i>{{ quote.name }}</i></b></li>
Now, instead of showing the quotes as you did before, only a preview of the full quote field is displayed along with the highlighted search query.
Boosting Performance
Full-text search is an intensive process. To combat slow performance, you can:
- Save the search vectors to the database with SearchVectorField. In other words, rather than converting the strings to search vectors on the fly, we'll create a separate database field that contains the processed search vectors and update the field any time there's an insert or update to either the
quoteornamefields. - Create a database index, which is a data structure that enhances the speed of the data retrieval processes on a database. It, therefore, speeds up the query. Postgres gives you several indexes to work with that might be applicable for different situations. The GinIndex is arguably the most popular.
To learn more about performance with full-text search, review the Performance section from the Django docs.
Search Vector Field
Start by adding a new SearchVectorField field to the Quote model in quotes/models.py:
from django.contrib.postgres.search import SearchVectorField # new
from django.db import models
class Quote(models.Model):
name = models.CharField(max_length=250)
quote = models.TextField(max_length=1000)
search_vector = SearchVectorField(null=True) # new
def __str__(self):
return self.quote
Create the migration file:
$ docker-compose exec web python manage.py makemigrations
Now, you can only populate this field when the quote or name objects already exists in the database. Thus, we need to add a trigger to update the search_vector field whenever the quote or name fields are updated. To achieve this, create a custom migration file in "quotes/migrations" called 0003_search_vector_trigger.py:
from django.contrib.postgres.search import SearchVector
from django.db import migrations
def compute_search_vector(apps, schema_editor):
Quote = apps.get_model("quotes", "Quote")
Quote.objects.update(search_vector=SearchVector("name", "quote"))
class Migration(migrations.Migration):
dependencies = [
("quotes", "0002_quote_search_vector"),
]
operations = [
migrations.RunSQL(
sql="""
CREATE TRIGGER search_vector_trigger
BEFORE INSERT OR UPDATE OF name, quote, search_vector
ON quotes_quote
FOR EACH ROW EXECUTE PROCEDURE
tsvector_update_trigger(
search_vector, 'pg_catalog.english', name, quote
);
UPDATE quotes_quote SET search_vector = NULL;
""",
reverse_sql="""
DROP TRIGGER IF EXISTS search_vector_trigger
ON quotes_quote;
""",
),
migrations.RunPython(
compute_search_vector, reverse_code=migrations.RunPython.noop
),
]
Depending on your project structure, you may need to update the name of the previous migration file in
dependencies.
Apply the migrations:
$ docker-compose exec web python manage.py migrate
To use the new field for searches, update SearchResultsList like so:
class SearchResultsList(ListView):
model = Quote
context_object_name = "quotes"
template_name = "search.html"
def get_queryset(self):
query = self.request.GET.get("q")
return Quote.objects.filter(search_vector=query)
Update the <li></li> in quotes/templates/search.html again:
<li>{{ quote.quote | safe }} - <b>By <i>{{ quote.name }}</i></b></li>
Index
Finally, let's set up a functional index, GinIndex.
Update the Quote model:
from django.contrib.postgres.indexes import GinIndex # new
from django.contrib.postgres.search import SearchVectorField
from django.db import models
class Quote(models.Model):
name = models.CharField(max_length=250)
quote = models.TextField(max_length=1000)
search_vector = SearchVectorField(null=True)
def __str__(self):
return self.quote
# new
class Meta:
indexes = [
GinIndex(fields=["search_vector"]),
]
Create and apply the migrations one last time:
$ docker-compose exec web python manage.py makemigrations
$ docker-compose exec web python manage.py migrate
Test it out.
Conclusion
In this tutorial, you were guided through adding basic and full-text search to a Django application. We also took a look at how to optimize the full-text search functionality by adding a search vector field and a database index.
Grab the complete code from the django-search repo.