 Amir Tadrisi
Amir Tadrisi
In this tutorial, you'll learn how artificial intelligence (AI) can empower us to create educational platforms that are smarter, more personalized, and more effective than ever by leveraging the latest advancements in AI technology such as GPT-3 and ChatGPT.
Whether you're an educator, developer, or just curious about the intersection of AI and education, this tutorial can inspire you to take advantage of AI to build better educational platforms.
Objectives
By the end of this tutorial, you should be able to:
- Describe the fundamentals of Large Language Models (LLMs), GPT-3, and indexing.
- Train a model on a blog post.
- Develop an API capable of answering questions about the blog post.
- Create a user interface for interacting with the API.
What We're Building
In this tutorial, we'll be creating a comprehensive application that leverages the power of AI to learn from blog posts and provide relevant answers to user queries. This application consists of three main components: the training process, the API, and the user interface.
First, we'll walk through the process of training an AI model on a specific blog post. This will enable the model to learn and understand the content of the post, effectively turning it into a knowledgeable resource for answering questions related to the post.
Next, we'll develop an API that can receive questions from users and provide corresponding answers based on the knowledge the AI model has acquired during the training process. This API serves as the core of our application, bridging the gap between the AI model and the user interface.
Finally, we'll create an interface where users can submit their questions. This front-end component will communicate with the API to send user queries and display the responses it receives from the API.
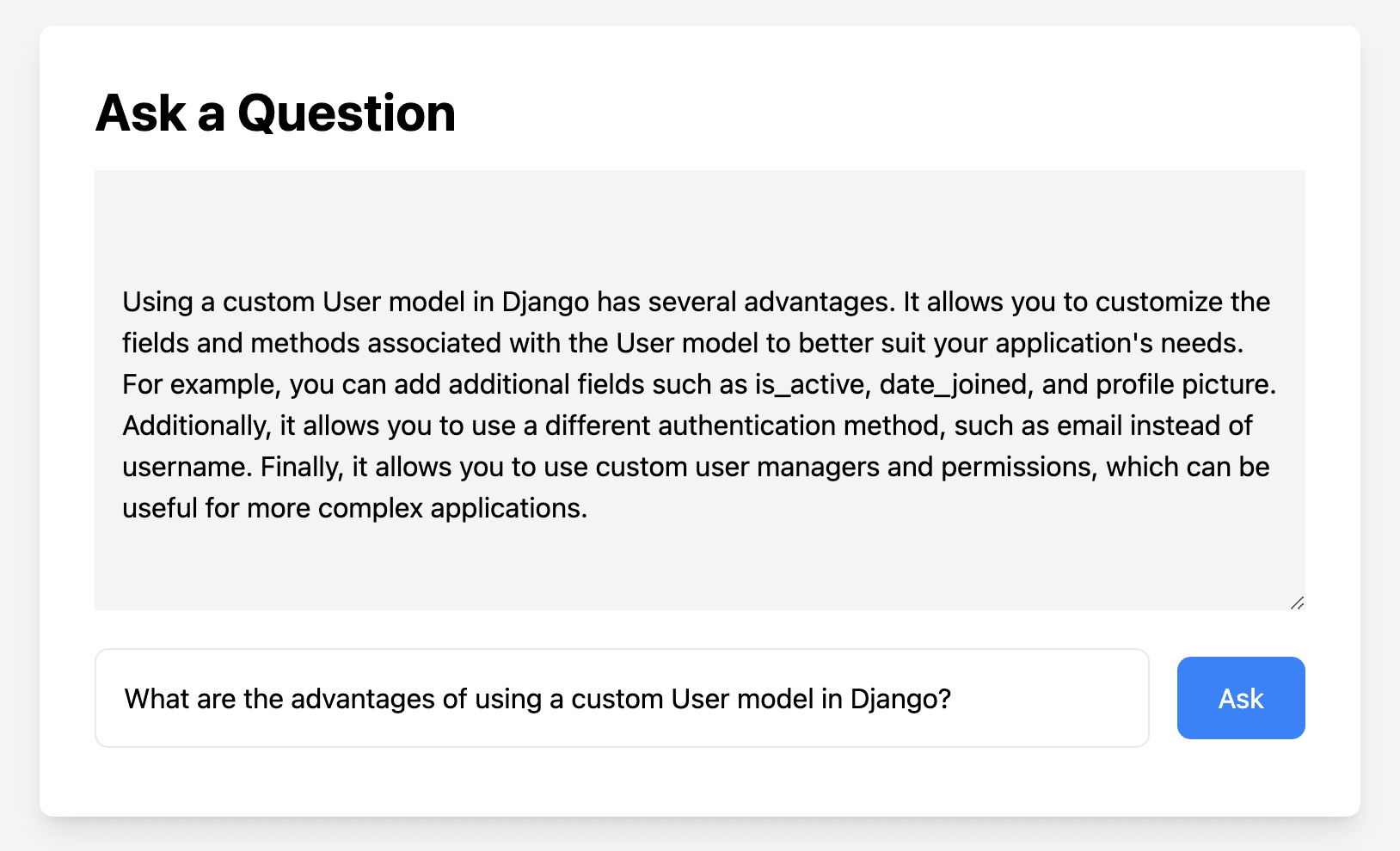
Final app:
Terminology
Before jumping into the tutorial, let's start with some terminology...
AI, LLM, GTP-3, and Chatgpt
Artificial intelligence (AI) has been rapidly evolving over the past few years and has become a hot topic in various fields. AI refers to the ability of machines to perform tasks that typically require human intelligence, such as reasoning, learning, and problem-solving. One of the most notable recent advancements in AI has been the development of Large Language Models (LLMs) such as GPT-3 and ChatGPT.
A Large Language Model (LLM) is an artificial intelligence system designed to understand and generate natural language text. It uses machine learning algorithms, typically based on deep neural networks, to analyze and model patterns in language data. The goal of a Large Language Model is to be able to generate text that is fluent and coherent, similar to how a human would write or speak.
These models are typically trained on vast amounts of text data, such as books, articles, and websites, and can learn to understand language at a very sophisticated level. Large Language Models are used in a wide range of applications, including chatbots, virtual assistants, language translation, text summarization, and content generation. Some examples of large language models include OpenAI's GPT-3, Google's BERT, and Facebook's RoBERTa.
GPT-3 (Generative Pre-trained Transformer 3) is a powerful language model developed by OpenAI that can generate human-like responses to natural language prompts. It has been trained on an enormous corpus of text data and has the ability to complete tasks such as language translation, question-answering, and even generating creative writing.
ChatGPT is a variant of GPT that has been specifically trained on conversational data. It can engage in natural language conversations with users, providing intelligent responses that simulate human-like interactions. With its ability to understand natural language and respond in a conversational manner, ChatGPT is a powerful tool for developing conversational AI applications such as chatbots and virtual assistants.
Prompt Engineering
A prompt is a specific question or statement that you give to a machine to get a response. It's like giving a task to a computer and asking it to complete it for you. For example, you might give a prompt to a machine that asks, "What is the capital of France?", and then the machine will respond with "Paris".
In the context of AI, prompts are used to help machines learn and understand specific tasks. For instance, if you want a machine to learn how to answer math problems, you can give it prompts that contain math questions and their answers. The machine will then use these prompts to learn how to answer math problems on its own.
In developing an educational platform, prompts can be used to help machines understand how to provide personalized learning experiences for each user. By giving a machine prompts that contain information about a user's learning preferences and level of knowledge, the machine can generate responses that are tailored to that user's needs.
Prompt engineering is a technique used to fine-tune the performance of language models like GPT-3 and ChatGPT to specific tasks. It involves creating a set of prompts that the model is trained on, which can help improve its accuracy and performance for that particular task. By leveraging the power of GPT-3 and ChatGPT through prompt engineering, we can develop intelligent educational platforms that provide personalized learning experiences for users.
LLMs and External Data
Sometimes a LLM may not have access to all the relevant information needed to generate high-quality text. This is especially true when it comes to generating text on a specific topic or domain. In such cases, connecting the LLM to external data, such as blog posts, can be extremely useful.
For example, imagine a scenario where a programming blog post has been written about a new coding framework or tool. Readers may have questions about how to use the framework or how it compares to other similar tools. By connecting an LLM to the blog post, the model can learn more about the specific programming language, syntax, and functionality of the framework. When readers ask questions, the LLM can then use this knowledge to provide more accurate and informative responses.
In this case, the LLM would be trained with the blog post data or documentation and then integrated with a chatbot or other natural language processing system that can handle reader questions. When a reader asks a question, the LLM can analyze the text and generate a response that draws on its understanding of the programming framework described in the blog post or the documentation. This can help to provide more relevant and accurate answers, while also saving time and effort for the author and readers alike.
However, one of the biggest limitation of the LLMs is context size. For example, Davinci’s engine limit is 4096 tokens, so our ability to connect LLMs to external data is limited by the context size.
To overcome this limitation, we're going to use LlamaIndex (GPT Index) to connect GPT-3 to the external data without being worried about the prompt size limitations. LlamaIndex works as an interface between our external data and LLMs.
Now, let's get started with the implementation of our project.
Configuring an Index
In this section, we'll use a local markdown file as our external data source to create an index and query it using LlamaIndex. By the end, you should understand how to work with indexes in LlamaIndex.
LlamaIndex
Create a new directory, and install the LlamaIndex package using pip:
$ mkdir python-openai && cd python-openai
$ python3.11 -m venv env && source env/bin/activate
(env)$ pip install llama-index==0.4.24 tiktoken==0.3.0 langchain==0.0.106 python-dotenv==1.0.0
Feel free to swap out virtualenv and Pip for uv, Poetry, or Pipenv. For more, review Modern Python Environments.
To use OpenAI's GPT-3 API, you'll need to sign up for an OpenAI account and create an API key. Follow the instructions provided by OpenAI to create an account and create an API key.
Using OpenAI's GPT-3 API has some cost. Make sure to check the pricing before using it. Also, set soft and hard limits for your API key to avoid unexpected charges.
Once you have your API key, in the root of the project, create a file called .env:
OPENAI_API_KEY=your_api_key
Now, create a new folder called "data", and inside it create a new file called cv.md:
John Doe
123 Main Street, Anytown USA | (555) 555-1234 | [email protected]
Summary
Highly motivated and results-oriented professional with 5+ years of experience in project
management and team leadership. Skilled in developing and implementing successful
strategies to improve business operations and increase profitability. Strong interpersonal
and communication skills, with the ability to build and maintain relationships with
clients and stakeholders at all levels.
Next, in the project root, create a new file called index.py:
import os
from dotenv import load_dotenv
from llama_index import GPTSimpleVectorIndex, SimpleDirectoryReader
load_dotenv()
openai_api_key = os.environ.get('OPENAI_API_KEY')
documents = SimpleDirectoryReader('data').load_data()
index = GPTSimpleVectorIndex(documents)
name = index.query("What is the candidate's name?")
address = index.query("Where is the candidate's address?")
print(name)
print(address)
Run the following command in the terminal:
(env)$ python index.py
You should see something similar to:
John Doe
John Doe's address is 123 Main Street, Anytown USA.
LlamaIndex by default uses OpenAI's
text-davinci-003model as its LLM predictor. For more on this, review Customizing LLM’s.
As you can see, we first loaded the document and then created an index over it. Then, we asked the index to query the document and return the name and address of the candidate.
Why Create an Index? Indexing is essential for handling external data sources when working with large language models like GPT. It enables faster retrieval, better management of context size limitations, improved accuracy, and scalability.
To learn more about indexing, review How Each Index Works from the official documentation.
Save and Load the Index
Sometimes you may want to save the index for later use, to do that, you can use the save_to_disk method:
# save to disk
index.save_to_disk('index.json')
# load from disk
index = GPTSimpleVectorIndex.load_from_disk('index.json')
Data Connectors
In the above example, we used a markdown file as our external data, but with LlamaIndex you can use a variety of external data types, like:
- Databases
- CSV files
- PDF files
- Google Docs
- Notion
- Slack
- Discord
- Web pages
To find the full list of supported data connectors, visit Llama Hub.
Developing a Prompt
Let's train our model with the Creating a Custom User Model in Django article.
Load and Index the External Data
Use the Simple Website Loader from LlamaIndex to load the data and create an index for it. Open the index.py file and replace the content with the following:
import os
from dotenv import load_dotenv
from llama_index import GPTSimpleVectorIndex, QuestionAnswerPrompt, download_loader
load_dotenv()
openai_api_key = os.environ.get('OPENAI_API_KEY')
SimpleWebPageReader = download_loader("SimpleWebPageReader")
loader = SimpleWebPageReader()
documents = loader.load_data(urls=['https://testdriven.io/blog/django-custom-user-model/'])
index = GPTSimpleVectorIndex(documents)
Create a Prompt Template
Next, let's develop a prompt template that encourages the model to provide a more accurate and detailed response based on the context. Add the following code to the end of the index.py file:
QA_PROMPT_TMPL = (
"Hello, I have some context information for you:\n"
"---------------------\n"
"{context_str}"
"\n---------------------\n"
"Based on this context, could you please help me understand the answer to this question: {query_str}?\n"
)
QA_PROMPT = QuestionAnswerPrompt(QA_PROMPT_TMPL)
Ask a Specific Question
To formulate a specific question related to the content of the article, which should result in a more accurate response from the model, add the following code to the end of the index.py file:
query_str = "What are the advantages of using a custom User model in Django?"
Query the Indexed Data
Now, in order to search for the most relevant context and generate a response based on the context and question, we can use the index.query() method with the question and prompt template:
response = index.query(query_str, text_qa_template=QA_PROMPT)
print(response)
Add the above code to the end of index.py, then and run the following command in the terminal:
(env)$ python index.py
You should see an output similar to the following:
Using a custom User model in Django has several advantages. First, it allows you to
customize the authentication process to better suit your needs. For example, you can
use an email address instead of a username for authentication, or you can add
additional fields to the User model to store additional information about the user.
Additionally, it allows you to easily extend the User model with custom fields and
methods, making it easier to add custom functionality to your application. This can
be especially useful when integrating with third-party authentication systems, such
as OAuth, as it allows you to easily customize the authentication process to fit your
needs. Finally, it allows you to easily integrate with third-party authentication systems,
such as OAuth, making it easier to add authentication features to your application.
By following these steps and ensuring that the question is specific and directly related to the content of the article, the model should provide more accurate and relevant answers. Keep in mind that the performance of the model can still vary, and you might need to experiment with different prompt templates and questions to achieve the best results.
Building an API
In this section, we'll create an API using Django and Django REST Framework that can communicate with our LLM and the external data.
Let's create a new Django project called llm_api inside the "python-openai" directory.
Make sure to remove the "data" directory, index.py file, and index.json file from the "python-openai" directory before proceeding.
(env)$ pip install django==4.1.7 djangorestframework==3.14.0 django-cors-headers==3.14.0
(env)$ django-admin startproject llm_api && cd llm_api && python manage.py startapp api
Create a new directory called "utils" in the root of the Django project. Then, add a new file called create_index.py to that newly create directory:
import os
from dotenv import load_dotenv
from llama_index import GPTSimpleVectorIndex, QuestionAnswerPrompt, download_loader
load_dotenv()
openai_api_key = os.environ.get('OPENAI_API_KEY')
SimpleWebPageReader = download_loader("SimpleWebPageReader")
loader = SimpleWebPageReader()
documents = loader.load_data(urls=['https://testdriven.io/blog/django-custom-user-model/'])
index = GPTSimpleVectorIndex(documents)
index.save_to_disk('./indexed_articles/django_custom_user_model.json')
Next, create a directory called "indexed_articles" in the root of the Django project, and then run the following command in the terminal to save the index to disk:
(env)$ python utils/create_index.py
Your directory structure should now look like this:
python-openai
├── .env
└── llm_api
├── api
│ ├── __init__.py
│ ├── admin.py
│ ├── apps.py
│ ├── migrations
│ │ └── __init__.py
│ ├── models.py
│ ├── tests.py
│ └── views.py
├── indexed_articles
│ └── django_custom_user_model.json
├── llm_api
│ ├── __init__.py
│ ├── asgi.py
│ ├── settings.py
│ ├── urls.py
│ └── wsgi.py
├── manage.py
└── utils
└── create_index.py
To create the API endpoint that will handle the user's questions, add the following to api/views.py:
import os
from django.conf import settings
from django.http import JsonResponse
from django.views import View
from dotenv import load_dotenv
from llama_index import GPTSimpleVectorIndex, QuestionAnswerPrompt, download_loader
from rest_framework.decorators import api_view
from rest_framework.response import Response
class AskView(View):
def get(self, request, *args, **kwargs):
query_str = request.GET.get('question', None)
if not query_str:
return JsonResponse({"error": "Please provide a question."}, status=400)
# Load the index from disk
load_dotenv()
openai_api_key = os.environ.get('OPENAI_API_KEY')
index_file_path = os.path.join(settings.BASE_DIR, 'indexed_articles', 'django_custom_user_model.json')
index = GPTSimpleVectorIndex.load_from_disk(index_file_path)
QA_PROMPT_TMPL = (
"Hello, I have some context information for you:\n"
"---------------------\n"
"{context_str}"
"\n---------------------\n"
"Based on this context, could you please help me understand the answer to this question: {query_str}?\n"
)
QA_PROMPT = QuestionAnswerPrompt(QA_PROMPT_TMPL)
answer = index.query(query_str, text_qa_template=QA_PROMPT)
return JsonResponse({'answer': answer.response})
def post(self, request, *args, **kwargs):
# Handle POST requests if needed
pass
In this view, we're accepting GET requests with a question query string -- i.e., ?question='What are the advantages of using a custom User model in Django?'. We then load the index that we previously created from disk and use it to query the external data for the answer.
Next, update api/urls.py like so to create a URL pattern for our endpoint:
from django.urls import path
from .views import AskView
urlpatterns = [
path('ask/', AskView.as_view(), name='ask_view'),
]
Now, we need to include the API app URLs in the project's main URLs file, lms_api/urls.py:
from django.contrib import admin
from django.urls import path, include
urlpatterns = [
path('admin/', admin.site.urls),
path('api/', include('api.urls')),
]
To test the API, run the Django development server:
(env)$ python manage.py runserver
You can now test the API by sending a GET request to /api/ask/ with the question parameter. For example:
To prepare our API for handling a UI, we need to configure django-cors-headers within the Django settings file.
First, add it to your INSTALLED_APPS:
INSTALLED_APPS = [
...
'corsheaders',
...
]
Add corsheaders.middleware.CorsMiddleware to the top of your MIDDLEWARE:
MIDDLEWARE = [
'corsheaders.middleware.CorsMiddleware',
...
]
Finally, add the following to the end of the file to whitelist our frontend URL that we're going to set up in the next step:
CORS_ALLOWED_ORIGINS = [
"http://localhost:8080",
]
Now run python manage.py migrate to apply the migrations.
Developing the UI
In this section, we'll create a simple UI using pure HTML and TailwindCSS. The frontend is separate from the Django project, so we'll use Python's http.server module to serve the static files.
Start by creating a new directory called "frontend" within the "python-openai" directory. Then, within "frontend", create a new file called index.html:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Question and Answer</title>
<script src="https://cdn.tailwindcss.com"></script>
<script>
function sendQuestion() {
document.getElementById("loading").classList.remove("hidden");
document.getElementById("answer").classList.add("hidden");
fetch(
'http://localhost:8000/api/ask/?question=' +
encodeURIComponent(document.getElementById('question').value)
)
.then((response) => response.json())
.then((data) => {
document.getElementById("answer").textContent = data.answer;
document.getElementById("loading").classList.add("hidden");
document.getElementById("answer").classList.remove("hidden");
})
.catch((error) => {
console.error("Error fetching data:", error);
document.getElementById("loading").classList.add("hidden");
document.getElementById("answer").textContent = "Error: Unable to fetch data";
document.getElementById("answer").classList.remove("hidden");
});
}
</script>
<style>
@keyframes spin {
to {
transform: rotate(360deg);
}
}
.animate-spin {
animation: spin 1s linear infinite;
}
</style>
</head>
<body class="bg-gray-100 min-h-screen">
<div class="container mx-auto py-8">
<div class="bg-white shadow-lg rounded-lg p-8">
<h1 class="text-3xl font-bold mb-4">Ask a Question</h1>
<textarea id="answer" class="w-full h-64 p-4 bg-gray-100 mb-4" readonly></textarea>
<!-- Loading message -->
<!-- Loading spinner -->
<div
id="loading"
class="hidden w-16 h-16 border-t-4 border-blue-500 border-solid rounded-full animate-spin mx-auto my-8"
></div>
<div class="flex items-center space-x-4">
<input id="question" type="text" placeholder="Type your question here" class="flex-grow p-4 border rounded-lg">
<button
class="bg-blue-500 text-white py-3 px-6 rounded-lg"
onclick="sendQuestion()"
>
Ask
</button>
</div>
<div class="htmx-indicator h-2 w-2 bg-blue-500 invisible rounded-full"></div>
</div>
</div>
</body>
</html>
With the Django development server running within one terminal window, open a new terminal window, navigate to the "frontend" directory, and then run the Python server:
$ python -m http.server 8080
You can now open the frontend in your browser at http://localhost:8080. By clicking on the Ask button, you should see the answer to the question you entered.
Since this is experimental code, it can take a few seconds to get the answer.
Conclusion
In this tutorial, we've looked at how to leverage AI via OpenAI's powerful language model, GPT, with Python to develop an interactive learning application. We also learned how to use external data sources to improve the accuracy of our AI model and bring up-to-date information to our language model.
We've only touched the surface of what can be built with Python and OpenAI. The power of GPT and other AI technologies, combined with the versatility of Python, offers a vast array of possibilities for developers to explore and create innovative solutions.
The repository for this tutorial is available on GitHub.