 Kovid Rathee
Kovid Rathee
Machine learning (ML) is a relatively new field of work compared to general application programming. Now that hardware and software both exist to support large-scale ML projects to enable better decision-making for companies, the technology landscape has exploded with tools and solutions for ML. This has given rise to a new field called MLOps. As described in an Introduction to Machine Learning Reliability Engineering, MLOps applies the best practices from DevOps -- collaboration, version control, automated testing, compliance, security, and CI/CD -- to productionizing ML.
With that in mind, in this article, we'll review the main tools and technologies you need to get started with ML development, concentrating specifically on MLOps and how MLOps is central to efficiently productionizing ML models.
Contents
ML Lifecyle
Although the MLOps domain hasn't been around for very long, the technology landscape of MLOps is vast because of how complex the ML lifecycle is. Throughout this article, we'll discuss the following themes in ML development:
- Data and Feature Management
- Data stores
- Data preparation
- Data exploration
- Feature store
- Model Development
- Model registry
- Model training and validation
- Version control
- Operationalization
- Automation testing
- Continuous Integration, Deployment, and Training (CI/CD/CT)
- Model serving infrastructure
- Explainability
- Reproducibility
- Monitoring
- Business performance monitoring
- Model monitoring
- Technical / system monitoring
- Alerting
- Auto-retraining
Keeping these themes in mind, your typical ML lifecycle consists of the following stages, sub-stages, and components:
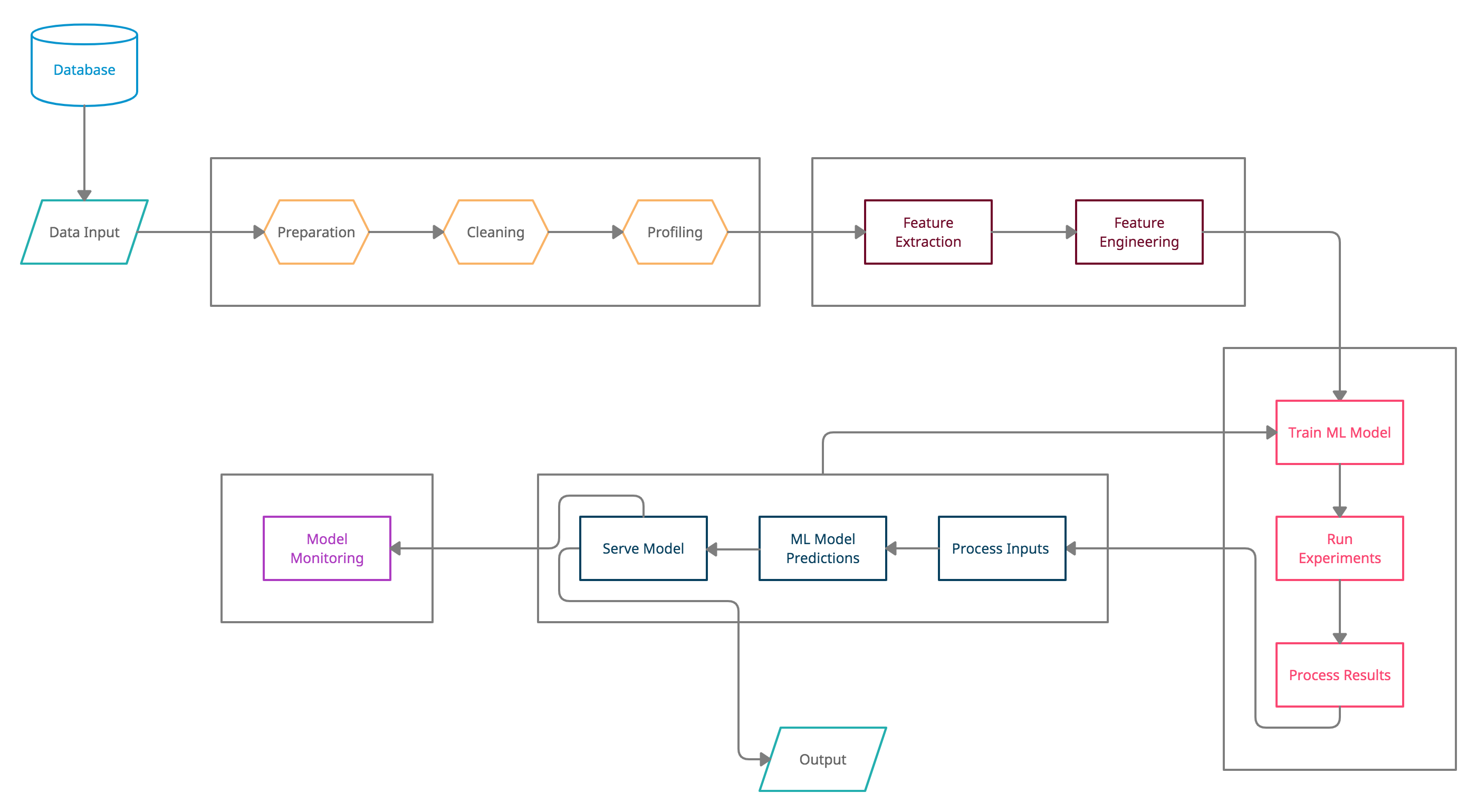
Keep in mind that the ML lifecycle presented above is the desired lifecycle. Many of the listed components aren't used in most lifecycles since MLOps isn't a mature field yet. Companies should work on refining their ML lifecycle as they build and scale their ML offerings.
Let's look at each stage and component in greater detail along with the associated MLOps tools.
Data and Feature Management
Data Stores
ML engineers consume data from databases, warehouses, and lakes. They also consume data directly from third-party tools, APIs, spreadsheets, text files, and whatnot. ML work usually involves storing multiple versions of data after cleaning, pivoting, enriching, etc. For keeping the data generated by the intermediate steps in the ML development process, you can use one or more of the data stores listed below:
| Data Store | Purpose | Examples |
|---|---|---|
| Databases | Storing transactional and non-transactional non-analytical data | Relational (MySQL, Oracle, PostgreSQL, MS SQL Server), Non-relational (MongoDB, InfluxDB, Cassandra, Elasticsearch, CosmosDB, NeptuneDB) |
| Data Warehouses | Storing analytical data for OLAP | Redshift, Snowflake, Firebolt, Azure SQL DW, Teradata |
| Data Lakes | Storing all kinds of data for discovery and downstream delivery | Azure Blob Storage, Amazon S3 |
| Streaming | Temporarily storing real-time data for consumption by consumers (pub/sub, MQ) | Kafka, AWS Kinesis, SQS, RabbitMQ, ZeroMQ |
| Third-party Integrations | SaaS software products integral to the business | Salesforce, Pipedrive, SurveyMonkey, Google Forms |
| APIs | Data-based services or SaaS software products exposed as APIs | Google Maps API, Coinbase API, Yahoo Finance API |
| Spreadsheets and Flat Files | Widely used file formats because of operational ease of use and adoption | Microsoft Excel, Google Sheets |
Data Preparation
Once the data is collected, the next step is to prepare it for consumption. This step involves essential restructuring, formatting, and cleaning of the data. This is followed by the exploration and profiling as well as improving the quality of the data. Some of this work can be wholly manual, but the rest can be automated and built-in to the ML pipeline.
Data Exploration
To connect to the data sources mentioned earlier, you need an ML programming language, a good code editor (or an IDE) to write your program in, and tools specifically built to handle large amounts of ML data. With them in your toolkit, you can start exploring the data, writing SQL queries, and building PySpark transformations as you begin to develop an ML model.
| Resource Type | Purpose | Examples |
|---|---|---|
| Languages | Framework for writing ML code | Python, Julia, R, Scala, Java |
| IDEs | Integrated development environment enriched with tools, shortcuts, and integrations to help write and debug code faster | VSCode, Atom, Zeppelin, Jupyter, Databricks, Floyd, SageMaker |
| MPPs | Massively parallel processing systems exploiting the capabilities of distributed computing | Hadoop, Spark |
| Cloud Platforms | Cloud-based offerings for ML by major cloud providers like AWS and GCP along with niche players like DataRobot | BigML, Azure ML, Dataiku, H20, DataRobot |
Using a combination of two or more of these tools, you'll be in an excellent position to start writing your ML model. We'll talk about where to store the data you prepared to feed into your model and your ML model's actual code here shortly.
Feature Store
After cleaning, prepping, and profiling the data, you can then start building a feature store, which is a collection of data attributes (usually in a tabular form) used to create and train an ML model. It can be created in a database, a data warehouse, an object store, your local instance, and so forth.
Model Development
Model Registry
Creating ML models is an incremental process. The core idea is to keep improving the model, which is why MLOps adds another critical pillar of continuity called continuous training (CT). In addition to continuous integration (CI) and continuous deployment (CD), continuous training is central to the ML development lifecycle. To maintain model lineage, source code versioning, and annotations, you can use a model registry.
The model registry consists of all the information mentioned earlier and all the other possible information available for a given model. You can use tools like MLFlow model registry or SageMaker model registry for storing information about your model.
Metadata Store
At every step of the ML pipeline, a component makes decisions; these decisions are passed on to the next step of the pipeline. ML metadata stores help you to store and retrieve metadata about different steps in the pipeline. Metadata helps you trace back the decisions you made, the hyperparameters used, and the data used to train the model. You can use tools and libraries like Google's ML Metadata (MLMD) and Kubeflow's Metadata component as metadata stores.
Model Training and Validation
You can train and validate models using one or more of the data exploration section's resources. For instance, if you choose to write your code in Python, you'd have access to specific Python libraries for training and validation, such as TensorFlow, PyTorch, Theano, PySpark, etc.
| Library Name | Known For | Language |
|---|---|---|
| TensorFlow | Large scale ML and neural network deployments | Python, Java, JavaScript |
| PySpark/Spark | Large scale SQL-like data analysis | Python, Scala |
| Keras | Deep learning, neural networks | Python |
| Scikit-Learn | General purpose ML library for Python | Python |
| Brain.js | JavaScript library for ML and neural networks | JavaScript |
| MLLib | Runs on top of Spark | Python, Scala |
| OpenCV | ML and AI library specializing in computer vision | Java, Python |
Version Control
Source code versioning is one of the most critical areas in any software development. It enables teams to work on the same code so everyone can simultaneously contribute to the progress. Decades ago, Subversion, Mercurial, and CVS were the main version control systems. Now, Git is the de facto standard for version control. Git is open-source software (OSS) that you can install on your server. You can also choose to use one of the cloud-based services. Here's a list of some of the main ones:
| Product | Known For | Additional Info |
|---|---|---|
| GitHub | The de facto standard amongst SaaS offerings for Git | Git Cheatsheet by GitHub |
| GitLab | Most feature rich Git SaaS offering | Git Cheatsheet by GitLab |
| BitBucket | Native to the Atlassian stack, integrates well with JIRA, Confluence | Git Cheatsheet by Atlassian |
| AWS CodeCommit | Native to AWS, seamless integration with AWS services | Get Started with CodeCommit |
| Azure DevOps | Native to Azure, seamless integration with Azure services | Get Started with Azure DevOps |
Specialized Source Control for ML
You may also want to look at Data Version Control (DVC), which is another open-source software tool used for source control made solely for data science and ML projects. DVC is Git-compatible and is designed to support ML development by versioning the complete ML project end-to-end using a DAG-based format. This helps prevent repeated data processing if the underlying data doesn't change until a particular step in the DAG.
While Git was written for versioning application code, it wasn't meant to store large amounts of data used by ML models or support ML pipelining. DVC has attempted to address both of those things. DVC is agnostic to the storage layer and can be used with any source control service like GitHub, GitLab, etc.
Operationalization
Automation Testing
As mentioned in an Introduction to Machine Learning Reliability Engineering, there are two ways to test an ML model:
- Testing the coding logic of the model
- Testing the output/accuracy of the model
The former is, more or less, like testing software applications, which you should automate in the same way. The latter, however, involves testing model confidence, the performance of a significant model metric, etc. ML testing is usually done in a mixed fashion where some of the tests are automated and part of the pipeline while others are entirely manual.
Based on the stage of ML development, tests can be of two different types -- pre-training and post-training.
Pre-training tests don't require training parameters. These tests can check if (a) the model output lies within a specific expected range and (b) the ML model's shape aligns with the dataset. You can perform many of those tests manually.
Post-training tests are more impactful and carry more meaning because they run against trained model artifacts, which means that the ML model has already done its work before running the tests. This gives us much deeper insight into how the model is behaving.
Testing is an integral part of the development process. You can conduct different types of tests at various stages of your ML development workflow. Some of the possible tests are listed below:
| Test Type | Where To Test | Purpose |
|---|---|---|
| Unit tests | Local development environment | Immediate feedback |
| Integration tests | Local development environment | Catching regressions |
| Unit and integration tests | Lower, non-prod environments | Code promotion |
| Model validation tests | Lower, non-prod environments | Partial validation tests |
| End-to-end tests | Non-prod environments | System sanity |
| Model validation tests | Non-prod environments | Complete validation tests |
| End-to-end tests | Pre-prod environment | System sanity, production readiness |
| Model validation tests | Pre-prod environment | Complete validation tests, accuracy |
| Fuzzy tests | Pre-prod environment | System reliability |
| A/B tests | Pre-prod environment | Model comparison |
| Monitoring | Pre-prod and prod environments | Real-time feedback |
Continuous Integration, Deployment, and Training (CI/CD/CT)
Unlike in a software application where the data generated by the application is separated from application artifacts, in ML development, training data is conceptually very much a part of the model artifacts. You cannot test the model validity or goodness of the model without training. This is why the usual CI/CD process is enhanced for ML development by adding another component to it -- continuous training. Code integration and deployment are always followed by training. Once the model is trained, the cycle continues.
Model Serving Infrastructure
After creating your ML model, you have to decide where to deploy your models -- e.g., which platform will you use for serving your ML models. A host of options are available for serving models from your on-prem servers. On-prem servers may work for some use cases. For others, it can get extremely costly and difficult to manage at scale. Alternatively, you can serve your models using one or more cloud-based platforms like AWS, Azure, and GCP.
Whether you use an on-prem server, a cloud platform, or a hybrid approach, you'll still have options to deploy your models as executables directly on your instances or in containers. Many PaaS products that try to solve the end-to-end ML model serving problem exist. This is usually the last step of the ML model pipeline. After this, post-deploying activities like model monitoring remain.
Some of the common deployment options are:
| Deploy With | Deploy Where |
|---|---|
| Docker, Kubernetes, Knative, Kubeflow, KFServing, AngelML, BentoML, Clipper | Anywhere |
| AWS Lambda, AWS SageMaker, AWS ECS, AWS Elastic Interface | AWS |
| Azure Functions, Azure Container Instance | Azure |
| Google Cloud Run |
Monitoring
Monitoring the model involves three aspects:
- Technical/system monitoring looks at whether the model infrastructure is behaving properly and that the model is being served correctly. This involves taking care of service-level agreements by tracking service-level indicators and is taken care of by a Machine Learning Reliability Engineer.
- Model monitoring, meanwhile, monitors the model via its outputs, comparing the outputs with actual incoming data. Model monitoring is about continuously validating the predictions' accuracy by checking for false positives and negatives, precision, recall, F1-score, R-squared, bias, and many more.
- With business performance monitoring, it all comes down to whether the model is helping the business or not. You should be able to monitor the impact of experiments run by various teams. You should monitor the impact of the changes in the model pushed in a release and compare them with the previous results.
In a highly developed MLOps workflow, monitoring should be active rather than passive. You should define service-level objectives not just for infrastructure-related metrics but model-related metrics as well. Diligent monitoring of these metrics means defining service-level objectives and tracking whether service-level indicators breach service-level agreements or not. Doing this enables you to tweak and improve the model continuously. This is the final step of the ML workflow puzzle. The development cycle repeats from here onwards.
Alerting
Modern-day systems are so complex that it doesn't make sense for monitoring to be manual. You need software to figure out if other software is behaving correctly. Rather than going through application logs, decision trees, and recommendation logs manually, you should define rules on the monitoring data. The rules are based on service-level objectives and service-level agreements. When the rule conditions are breached, you can set up triggers. For example:
- Send a push notification to a pager application like PagerDuty.
- Send an alert in a collaborative communication tool like Slack, Microsoft Teams, etc.
- Send an email or a text message.
The channel you send the alert on depends upon the applications and processes you have in place for managing production issues. Alerting needs to be handled with care; otherwise, it can make your life hell by sending too many alerts. It's challenging to cut through the noise. You need to make conscious, thoughtful choices in order for your alerting system to work properly.
Auto-retraining
ML models only stay relevant if they are trained and re-trained continuously. The training and re-training can happen when there's new real data fed into the system and the predictions of the model are tested against real outputs. Monitoring feeds the alerting engine, but you can also configure the monitoring system to feed the model itself, creating a feedback loop going through the complete ML lifecycle. This is the most valuable feedback that the ML model can get because the feedback is coming after production deployment.
Depending on the implementation of a data model or the architecture of a project, a host of new paradigms like AutoML, AutoAI, self-tuning systems become very relevant. You can choose one of many tools that suits your requirements and find an efficient method to retrain your models. Remember that re-training doesn't result in code changes; it only provides new production data and the ML's model output to the ML model itself.
Conclusion
This article looked at how MLOps fits into the ML lifecycle. We also looked at the various tools that you'll need to be aware of and work with while developing, deploying, and serving ML models.
For more tools and frameworks, check out Awesome production machine learning repo.
As you're evaluating MLOps tools, keep in mind that most tools are relatively new, so few end-to-end workflows exist. Because of this, don't settle on a single platform. Make sure the tools can be moved in and out based on your needs.