 Nik Tomazic
Nik Tomazic
This article looks at how to avoid the object count query in Django pagination.
If you are using Postgres and would like to use an approximate count instead of entirely removing it, check out Approximate Counting in Django and Postgres.
--
Django's default Paginator relies on the object COUNT(*) query to calculate the number of pages. As your database grows, this query can become considerably slow and may end up causing most of the page load time -- sometimes over 90%.
In this article, we'll implement a paginator that skips the object COUNT(*) query. The implemented paginator assumes that knowing the number of pages isn't essential for your use case. In other words, the paginator won't know how many pages there are.
Contents
Project Setup
To make the tutorial easier to follow along, I've prepared a simple Django app. All the app does is store log messages in the database and returns them in a paginated API response.
If you want, you can follow along with your own Django project. However, your project might be a bit more difficult to benchmark.
First, clone the base branch of the GitHub repo:
$ git clone https://github.com/duplxey/django-count-avoid.git \
--single-branch --branch base && cd django-count-avoid
Next, create a new virtual environment and activate it:
$ python3 -m venv venv && source venv/bin/activate
Install the requirements and migrate the database:
(venv)$ pip install -r requirements.txt
(venv)$ python manage.py migrate
Populate the database:
$ python manage.py populate_db
Each run of the populate command will add 2.5 million records to the database. I suggest you run the command two or three times.
The command also creates a superuser with the following creds:
admin:password.
Run the server:
(venv)$ python manage.py runserver
Great, you've successfully setup the project.
Initial Benchmark
To benchmark the API, we'll use the Django Silk package. Django Silk is a simple tool for profiling and monitoring Django projects. It tracks database query times and view load times and helps identify bottlenecks in your project.
Silk is already installed if you're using the suggested log management project.
First, open your favorite web browser and navigate to http://localhost:8000/api/.
You'll notice a relatively long load time.
Next, navigate to http://localhost:8000/silk/requests/ to see the requests' statistics.
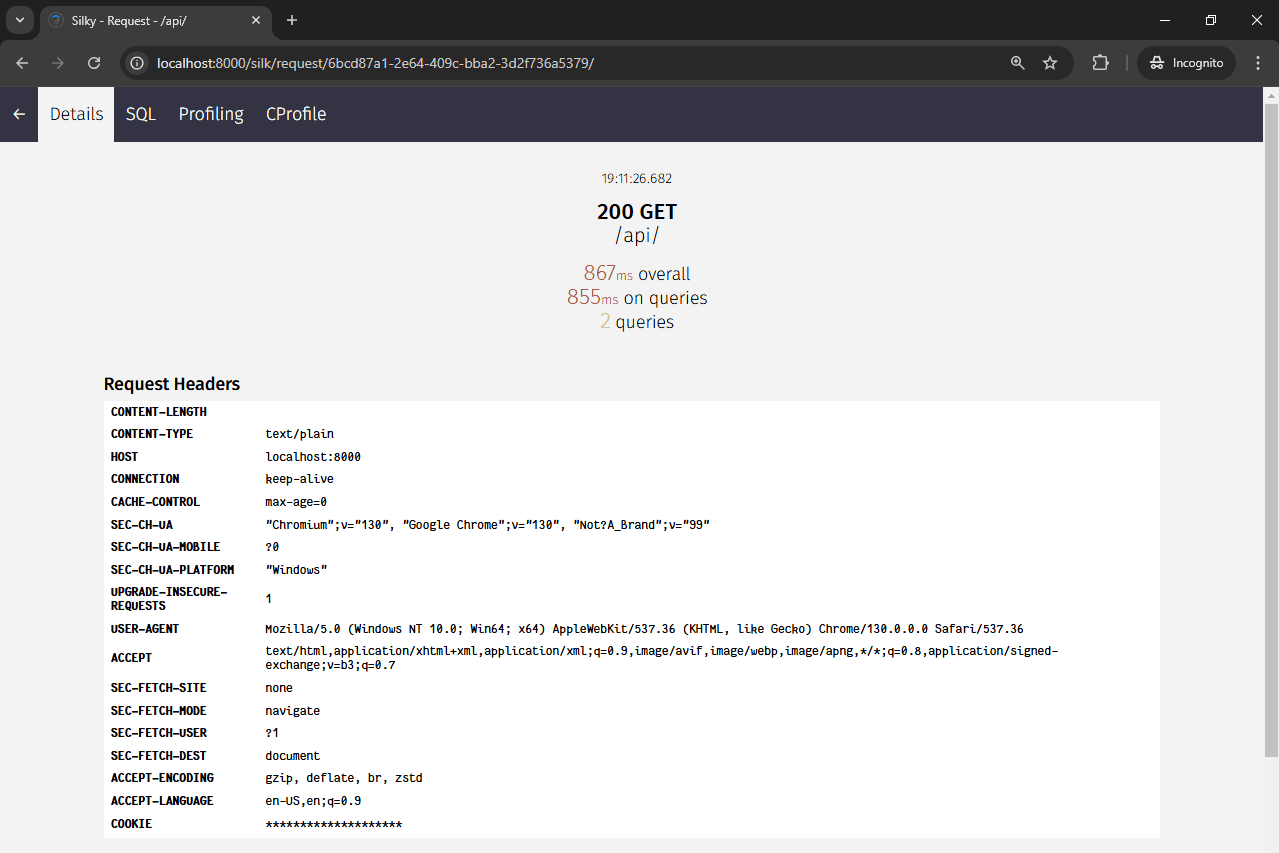
Ouch, the request took 867 milliseconds, 855 of which were spent on SQL queries.
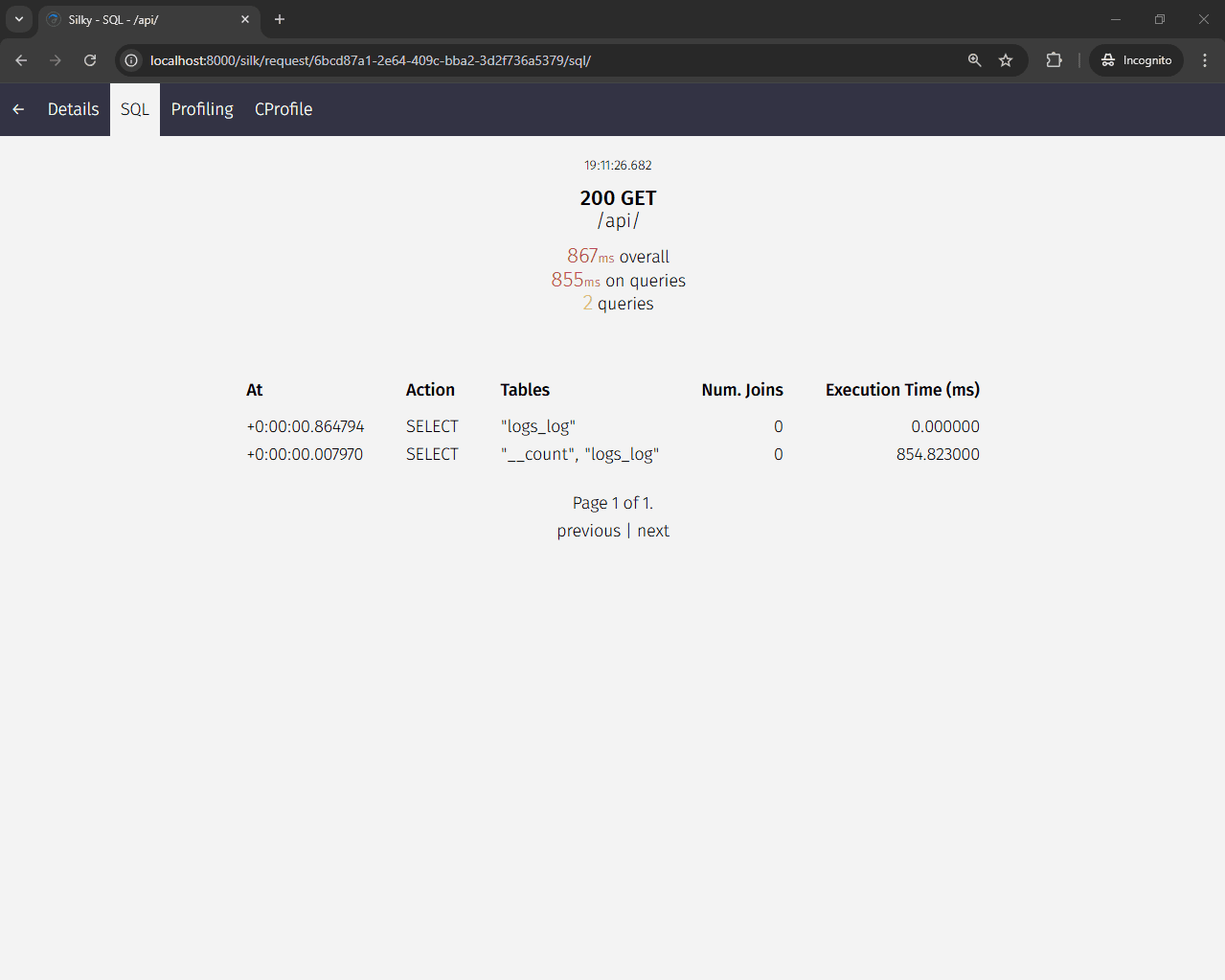
Selecting "SQL" in the navigation bar shows that the SQL query that took the most time was SELECT COUNT(*), which took 854 milliseconds.
Countless Paginator
Let's implement a paginator that doesn't require the SELECT COUNT(*) query.
To do that, we'll define two classes:
- A
CountlessPageclass (based on Django's Page class) - A
CountlessPaginatorclass (based on Django's Paginator class)
Create a paginators.py file within the logs app and put the following code inside:
# logs/paginators.py
import collections
from django.core.paginator import EmptyPage, PageNotAnInteger
from django.utils.translation import gettext_lazy as _
class CountlessPage(collections.abc.Sequence):
def __init__(self, object_list, number, page_size):
self.object_list = object_list
self.number = number
self.page_size = page_size
if not isinstance(self.object_list, list):
self.object_list = list(self.object_list)
self._has_next = \
len(self.object_list) > len(self.object_list[: self.page_size])
self._has_previous = self.number > 1
def __repr__(self):
return "<Page %s>" % self.number
def __len__(self):
return len(self.object_list)
def __getitem__(self, index):
if not isinstance(index, (int, slice)):
raise TypeError
return self.object_list[index]
def has_next(self):
return self._has_next
def has_previous(self):
return self._has_previous
def has_other_pages(self):
return self.has_next() or self.has_previous()
def next_page_number(self):
if self.has_next():
return self.number + 1
else:
raise EmptyPage(_("Next page does not exist"))
def previous_page_number(self):
if self.has_previous():
return self.number - 1
else:
raise EmptyPage(_("Previous page does not exist"))
class CountlessPaginator:
def __init__(self, object_list, per_page) -> None:
self.object_list = object_list
self.per_page = per_page
def validate_number(self, number):
try:
if isinstance(number, float) and not number.is_integer():
raise ValueError
number = int(number)
except (TypeError, ValueError):
raise PageNotAnInteger(_("Page number is not an integer"))
if number < 1:
raise EmptyPage(_("Page number is less than 1"))
return number
def get_page(self, number):
try:
number = self.validate_number(number)
except (PageNotAnInteger, EmptyPage):
number = 1
return self.page(number)
def page(self, number):
number = self.validate_number(number)
bottom = (number - 1) * self.per_page
top = bottom + self.per_page + 1
return CountlessPage(self.object_list[bottom:top], number, self.per_page)
Both classes are primarily based on Django's source code. The only two differences are that they skip the count query and use a different method to check whether the next and previous pages exist.
To determine whether the next page exists, we try to pass an extra object from the paginator to the page. In the page, we slice the object list back to its original size and check if an extra object is present. If so, the next page has at least one object; therefore, it exists.
In contrast, for the previous page, we just check if the page number is number > 1.
Next, use the CountlessPaginator in the index_view in logs/views.py like so:
# logs/views.py
def index_view(request):
logs = Log.objects.all()
paginator = CountlessPaginator(logs, 25) # modified
page_number = request.GET.get("page")
page_obj = paginator.get_page(page_number)
return JsonResponse(
{
"has_next": page_obj.has_next(),
"has_previous": page_obj.has_previous(),
"results": [log.to_json() for log in page_obj],
}
)
Don't forget about the import:
from logs.paginators import CountlessPaginator
Benchmark the app again.
The request now only takes 12 milliseconds. That's around 70 times faster than before.
Conclusion
In this article, we've looked at implementing a paginator that doesn't rely on counting objects.
By swapping the default Django paginator with a custom one, we significantly improved the paginated API response time. In our case, the response time went from around 800 milliseconds to 12 milliseconds.
For more information, check out the following resources: